2004-08-17
Adaptron Test Run-1 17th Aug, 2004
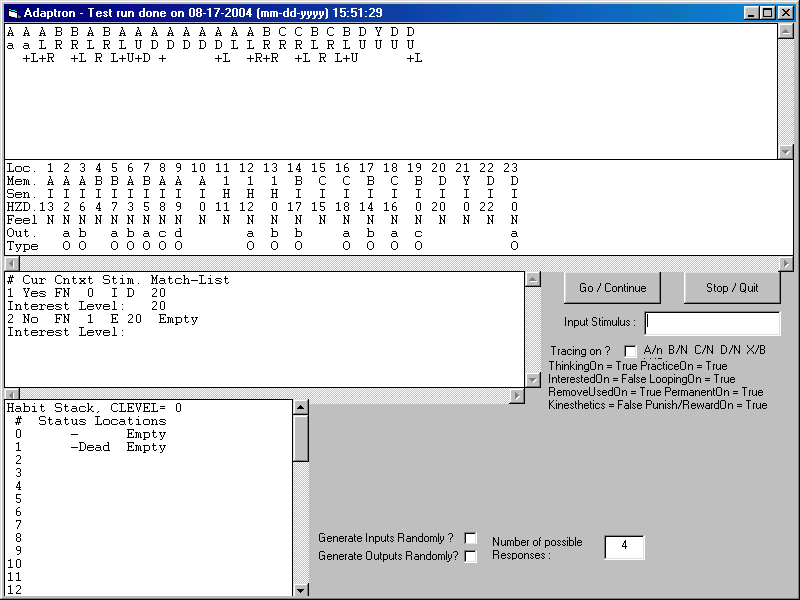
Test case #14 where D is initially rewarding but then does not reward.
Adaptron repeats trying an Up at B expecting a D with reward until it finally gives up at location 27.
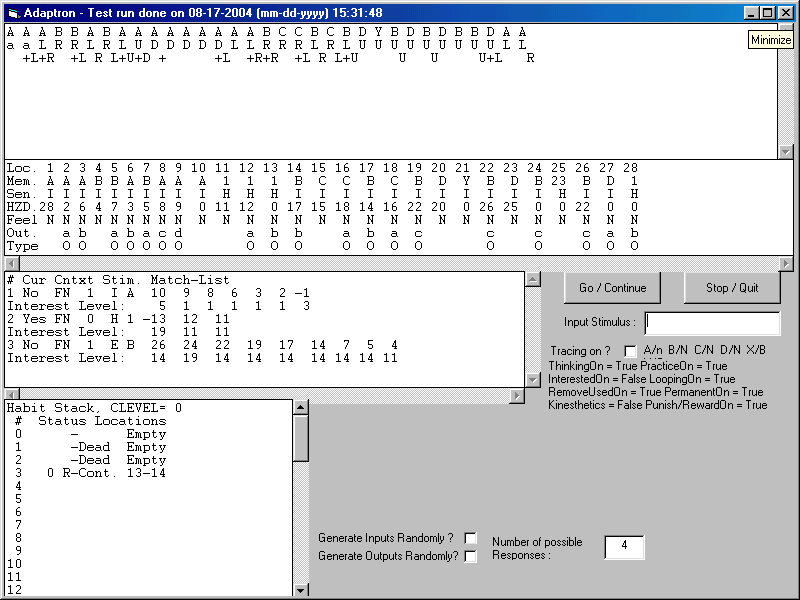
As the run below illustrates it did the Up at 24 by repeating the R-Habit at 22. It’s doing this because it thought about the D result and its most recent memory of D at 23 is it is unlearnt (actually at end of LTM because it was the context of the previously executing S-Habit to recognize D Y at 20 which failed).
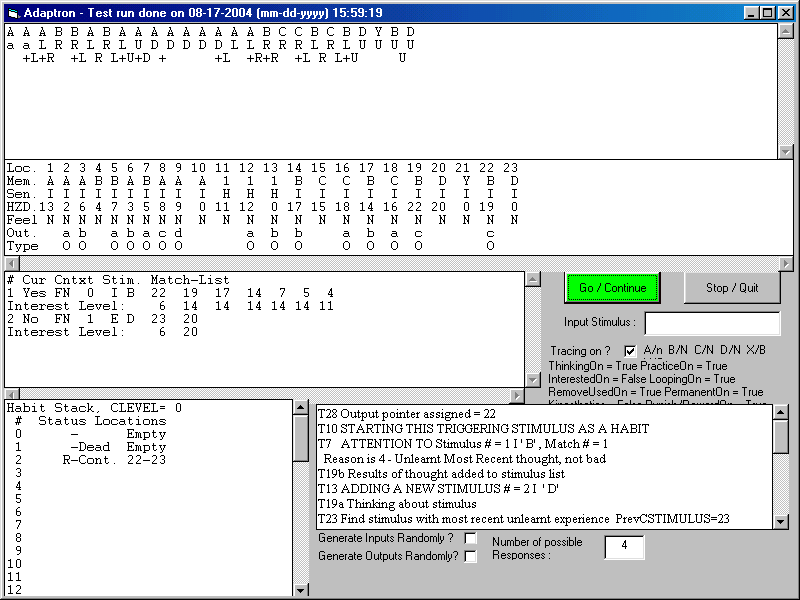
Here it continues to get the D after the reward and it immediately recognizes it as no longer associated with reward and finds it boring.