
2010
1st Jan, 2010 Change in Graduated readings
The change experienced between two graduated readings must be recognized independent of the actual reading. Thus it cannot be a ratio of the two readings but must be the difference between the readings. The orientation becomes order in time and cannot be part of the experience; it must be part of the change object. Thus 6,4 and 5,3 are the same change as 2,0. Also 4,6 and 3,5 are the same change as 0,2 which is a different change object from 2,0.
I have a problem with habit execution from LTM when dealing with graduated readings. LTM does not retain the absolute reading value and thus habit execution is based on the objects. All of these are the same object for graduated readings. When the sensors experience change and the change object is placed in memory as an S-Level 2 object it does not have a corresponding LTM location for execution because the habit execution process did not generate it. The solution may be as documented on 31st Dec 2009 and store the change binons and have the S-Habit execution expect them.
3rd Jan 2010 Change objects
I believe that we need to recognize the longest series of changes possible before reacting to them. This is similar to the concept we react to the largest combination of parts as a whole object rather than to the individual parts. When the parts change independently then we start treating them / reacting to them individually. So any sequence of changes gets treated as a whole object when it repeats. If any sub-sequence is found to repeat inside a different sequence then the sub-sequence is treated as a whole object. This concept was first questioned on the 7th Oct 2007. On 7th Feb 2008 I realized that a sequence of changes that did not meet our expectations was interesting and a sequence that was expected was boring. But it must wait for the end of the sequence that is boring before reacting because it is the whole sequence that is the object. Read 19th and 20th Jan 2009. On the 20th Jan 2009 I said, “This would result in long delays before any reflexive responses are performed if the environment is always changing because the same sequence must be experienced twice without anything in between." This means for graduated readings the sequence "12121212" will be reacted to upon the 3rd occurrence of the 1,2 sequence, which occurs at the 3rd 2. For graduated readings only the reading changes, the object stays the same and does not attract attention. If these were symbolic readings Adaptron's current reaction would be at the 3rd 1. For symbolic readings the object is changing and the reading is constant.
4th Jan 2010 Longest sequence
The above idea of 3rd Jan when applied to discrete / symbolic stimuli should also apply. We should recognize the longest sequence and react to it before reacting to any sub-sequences if they ever become independent. Thus the ABABABAB sequence should result in the 1st reflexive response after the 3rd B having become bored with the A,B sequence. There should also be a reflexive response after the 4th A having become bored with the B,A sequence.
Given the sequence ABADAEoABADAEm one would say that the repeated sequence is ABADAE. If it were ABADAEoABg then one would say the AB is the repeated sequence. But if we had AoAg or ABoAg we would not say A is a repeated sequence because it is only length 1. A sequence must consist of 2 or more stimuli. However the 2nd A would act as the trigger to start recognizing the repeat of any sequences. At a 2nd A one would be expecting a known sequence to be recognized or a novel one to occur due to an unexpected stimulus. This would be true for any sub-sequence. The unexpected stimulus indicates the sub-sequence has been recognized and it is an individual sub-sequence that can be reacted to individually.
This should also apply to the single A. In the ABADAE sequence A should become a part that is independent for reaction purposes. This principle applies to A in the role of a trigger because reaction is always based on a trigger. However A may still be part of a bigger sequence if it is the goal. For example in XABYADZAE A as an independent trigger stimulus terminates the XA, YA and ZA sequences for recognition as sub-sequences. This would mean the LTM trace for the YAD part would be YA and AD on first occurrence. The YAD sequence would not be stored. In the ABADAE the ABAD part should be stored as ABA and AD.
Maybe the idea from 22nd Jan, 2009 should be revisited for LTM storage representation. The example of ABABAMABAW would be stored as ABA12AMA4AW. 1 is (AB), 2 is (BA) and 4 is (12), which is ((AB)(BA)). The process would store the trigger and its next goal stimulus for any stimulus that has no expectations. This happens with the 1st A, the 1st B. It would store the 2nd A as the goal stimulus and not override / replace it with any next sequence that may contain it. This happens again with the MA sequence. The process would also store the trigger and its goal stimulus for any S-Habit that gets an unexpected goal stimulus. In this rule the trigger stored would be the one at the same level as the unexpected goal that was obtained. This happens at the AM and the AW. However when an expected sequence occurs it is stored in memory, for example, the 1st 1 is stored at location 4. Because it is the 1st 1 in LTM it has no expectations and is not replaceable according to the first rule above. Similarly the 4 at location 9 results from the 1 expecting the 2 and then getting it.
5th Jan 2010 Background recognition
With this new LTM sequence storage approach the recognized sequences just get longer and longer if I have the repeating sequence ABABABABABAB. The result is ABA121454787 where '5' is BAB, '7' is ABAB and '8' is BABA. When we repeat the AB sequence in our heads we will continue to hear a series of ABs or BAs and can switch between the two. We never hear the 3 or 4 stimulus long sequences. Also when we start up backgrounder recognition habits to detect alternate sequences which may have started with the goal stimulus (2nd part) of a just recognized sequence and these succeed they intersperse alternate sequences in the middle of the one we are trying to recognize. For example, the 2 between the two 1s. We need the two 1s beside each other if we are to recognize the AB pattern as boring.
Redo Interest
So given that the dependent sequence is 1=AB always expecting a C then the LTM trace is 1C with a redo interest of 1 so it continues to be interesting to do. When the 1D sequence occurs the sequence stimulus 1 becomes independent because there are 2 possible goals. This 1D in LTM will also have a redo interest of 1. When the next AB occurs there will be the two S-habits on the stack, one expecting the C and the other expecting the D. If either gets its expected goal then the redo interest in both is set to neutral so that the next sequence stimulus 1 that occurs is reacted to. If neither gets its expected goal because an unexpected stimulus occurs then both redo interests in LTM stay at 1 and the new memory trace also has a redo interest of 1.
6th Jan 2010 Sequences
The need to recognize the longest sequences of stimuli that repeat as a whole before starting to explore these sequences with reactions has resulted in the following ideas. Each stimulus at a single time (S-Level=1) needs to be flagged with two properties. One property is the fact that it has a dependent (consistent) goal (next) stimulus at the single time level (S-Level=1) and what is that stimulus. The second property is the fact that it has a dependent (consistent) trigger (previous) stimulus at the single time level (S-Level=1) and what is that stimulus. As soon as one or both of these properties becomes inconsistent (has an unexpected stimulus) then the stimulus is independent. A longest sequence is then delineated by having these occur at both ends. More specifically S-Level=1 independent stimuli with either or both of these properties cause an 'edge' in time. These edges finish one sequence and start another.
Short Term Memory
S-Level =1 stimuli that comprise a sequence can originate from any sense or P-Habit. The only criterion constraining the combination of stimuli at any level is that they are at the same S-Level to form a binon. The design of an algorithm to perform this will require a short-term memory (STM) of all the sub-sequences made up of dependent stimuli recognized so far up until an independent stimulus occurs. When an independent stimulus occurs the STM has recognized a sequence and is flushed, ready to recognize the next longest sequence. It is then at these edges in time that actions are performed and learnt. This STM will function somewhat similarly to my current S-Habit stack which looks for / is expecting repeated sequences. However the current S-Habit stack is really for learning action habits based on redo interest. I need a different structure that combines stimuli sequentially as they occur. The stimuli that are placed in this STM however, must be the ones attended to. The criteria for attention to a stimulus include its unexpectedness, the interest in its expectations and its role in completing an action habit. This has to be sorted out.
7th Jan 2010 Short Term Memory
I thought I would just need the one STM for the sequence of conscious stimuli. However once an A-Habit has been learnt and it is started as a subconscious action then it must continue to recognize the feedback stimuli between the responses. Should any of these be a sequence then a STM is needed to recognize them. So do I need an STM on each sense recognizing sequences? No, the action habit can fail as soon as any part of the expected sequence is not received. What about having a background recognition habit that is expecting a sequence? This should be the same as the A-Habit. It should fail as soon as any part of a sequence is unexpected. The STM of a sense should only be the previous S-Level=1 stimulus so that it can recognize a change at this level.
S-Level = 2 and higher stimuli that are recognized as an independent sequence will have their left and right edges properties set to independent.
STM algorithm
This first algorithm is based on left and right expectations.
At S-Level=1 last stim in STM must have either a right dependency, expected goal stim or -1.
if last stim in STM has -1 right dep then set right dep to new stim
if new stim has -1 left dep then set it to the last stim in STM
unless 1st stimulus then set left dep = 0 independent
if last stim in STM right dep is = new stimulus then
if new stim's left dep = last stim right dep then Add new stim to STM
and disregard if new stim's left dep <> last stim right dep [problem here]
else last stim becomes right indep = 0 and Flush STM to LTM, Add new stim in STM
Add to STM:
form combo at all levels based on new stim. If new stim is right independent then Flush
longest sequence in STM else if new stim right dep = -1 or is dep then finished the add
Flush STM:
Set longest sequence in STM left and right dep = 0 = independent
if to LTM then not attended to else set attend to the longest seq in STM
A simpler alternate algorithm that also gets rid of the problem recognizing CAB and BCA once ABC has been recognized and A is left independent is:
If new S-Level=1 stim is whole then flush STM to LTM & Start new seq
else if get repeat in STM then flush STM to LTM & Start new seq
else if not expecting then Add new
else if get expecting then Add new
else if get unexpected then flush STM to LTM & Start new seq
When Flush STM to LTM the sequence flushed is a whole.
When Start new seq if it is a whole then Flush STM as a whole to attend to
else there is no attend to done
When Add new if whole formed then Flush STM as a whole to attend to
else there is no attend to done
9th Jan 2010 Separation & Reading
When creating the change in reading object between two sequential readings I no longer needed the absolute values of the readings. The change object captures the difference in readings. The same would be true for creating a change in separation object. So how do I formulate the change in separation / reading combo? Take the following scenario.
Stim1 = 1ooo2ooooo4 changes to Stim2 = 2o4oo8 where the o's are not part of the pattern.
Using the separation object #27 = 2 / 4, a gap of 2 and a gap of 4 then Stim1 separation value is 4 and Stim 2 separation value is 2. The change in separation object #54 captures the change from 4 to 2 as -2.
Using the reading object #36 = 1/2/4, actually two reading objects combined (1/2 and 2/4) then Stim 1 reading value is 1 and Stim2 reading value is 2. The change in reading object #69 represents the change from 1 to 2 as +1.
The separation / reading object #99 combines 27 and 36. Is there a value for it? Both Stims have the same reading and separation objects and therefore this same separation / reading object #99. But object #99 does not uniquely identify each experience without a value of some sort. Do I need this unique experience identifier? If the readings are symbolic or sensors independent (discrete sense) I do. That's how I distinguish between ADo and AoD, which have the same reading object but different separation objects. Here the values are all zero and irrelevant.
For the separation / reading change object I can combine the two change objects 54 and 69 to represent the change.
10th Jan 2010 Absolute values
I've decided the answer is that I don't need the combination object #99's value. The reading and separation values are used to form the relative patterns and to form the change objects. They may be used to compare two identical objects in the same scene for their relative reading or size but not to identify the objects.
18th Jan 2010 STM, Attention and Habits
I currently have STM processing after determining which stimulus attracts attention. This stimulus is then put in STM if it is dependent (expecting only one next stimulus) else it ends the current STM stimulus (if any) and the STM or it becomes the attended to stimulus. The habit processing is done before selecting the attended to stimulus.
Habits are processed for three main reasons.
- Reduce the interest caused by a change because it was expected by a habit,
- To form result sequences from a trigger and goal, which are both permanent and
- To perform action sequences.
If I was to put STM processing before habit processing then if a stimulus is in STM then it is expecting only one next stimulus (the dependent one). It could reduce the interest in the expected stimulus if it occurred. But would one add it to STM at this point or wait for habits to be processed and to see if attention is paid to it? If it were to form an independent stimulus when combined with its expected stimulus the result would be available for the habits to process. If it were to form a dependent stimulus when combined with its expected stimulus the STM would contain the result. If there is a stimulus in STM and it does not get its expected stimulus then it would become independent and could be moved into LTM. So the answer would be yes, add the expected stimulus to STM before habit processing.
If STM were empty then habits would execute as they currently do and attention attracted as it currently does. Finally if the attended to stimulus was dependent then it would be put in STM as currently done unless it had already been added to STM before habit processing. The important feature is that independent stimuli sequences containing the latest S-Level=1 stimuli formed in STM are available for habit processing. The other feature needed is that if attention is attracted to a stimulus not added to STM then the contents of STM are disregarded and emptied.
Another feature is; if a stimulus in STM has no expected next stimulus then it waits for after attention to be paid before adding the next stimulus.
25th Jan, 2010 Repeated sequence ABABABAB
Now that I have STM working I am rethinking sequence recognition when a stimulus repeats. When presented with the series AAAA I have decided that reaction does not take place after the second A. Upon the second A you are bored because of the repeat but you are waiting to see if it is followed by another A as it was before. Previously I had Adaptron reacting as soon as it detected the repeat. This is where emotional intelligence kicks in. The need to practice the sequence again to see if it happens a second time before getting bored allows time for thinking to take place. If we react to the emotions too quickly there is no opportunity for thinking to intercede.
26th Jan, 2010 Resulting Stimuli
A new stimulus that results from the collapse of two permanent stimuli represents a sequence. Each of its parts is no longer reacted to separately since they have both been explored. This new resulting stimulus should now be treated as a new stimulus with no dependence / expected next stimulus and be placed on STM.
Permanent stimuli should also be put on STM and combined with any other permanent stimuli because there is no reaction being done after the trigger. A permanent stimulus would be on the STM with no expectation of a goal (independent) because many goals would have been experienced when it was being explored. It would accept any next permanent stimulus as a goal. It would then form all the S-Level combinations with it to the top resulting stimulus. This stimulus would stay in STM if it was permanent or if it had zero or one expected stimulus but would be put on the S-List if it were independent. However if the next stimulus were not permanent then STM would be flushed to LTM and the next stimulus handled as though STM was empty.
28th Jan, 2010 Permanent STM Stimuli
I need to layout the STM strategy dealing with permanent stimuli more accurately. Before S-Habit execution and attention processing STM may be empty or have a stimulus in it.
If it is empty then we just proceed with S-Habit execution etc. If it has a stimulus on it then we first look to see if any stimulus in STM repeats with any just perceived stimulus.
After S-Habit execution and attention processing there may or may not be a stimulus in STM. If there is none then the one attended to will be placed in STM if it is permanent or it is not independent. If however STM is not empty we must consider all the possibilities.
- Last STM = Permanent & Attend to = Permanent
- Last STM = Permanent & Attend to = Not permanent
- Last STM = Not permanent & Attend to = Permanent
- Last STM = Not permanent & Attend to = Not permanent
Repeated permanent stimuli
I have not put permanent stimuli into STM yet, they are still being processed by habit execution. But I have many situations where it makes an S-Level=1 stimulus permanent and stops responding to it so it is then stationary even though it could further explore. This is where thinking must intervene and do further look ahead based on experience and try unexplored sequences.
1st Feb, 2010 STM (Short Term Memory)
The only way a stimulus should be attended to - come out of STM after attention processing is if it is non-permanent and it is independent - has a RgtO of 0 - more than one expected next stimulus. Because only in this state are stimuli explored with responses. STM is never left with a non-permanent and independent highest S-level stimulus. Thus STM processing must combine permanent and non-permanent stimuli into higher level S-Habits. None of the lower level stimuli in STM that make up the highest S-level STM stimulus can be non-permanent and independent because they would have been flushed earlier for attention processing. An S-Level >1 permanent stimulus can be on STM consisting of two or more non-permanent stimuli if its parts have always occurred in the same sequence. Also two permanent stimuli could be in STM forming a new or dependent higher level stimulus on STM. A non-permanent dependent 1st stimulus followed by its expected permanent 2nd stimulus could be in STM forming either a dependent or a permanent stimulus. A permanent stimulus cannot have no expected stimulus (RgtO = -1). In other words a permanent stimulus cannot be new - have no expected stimulus. Also a permanent stimulus cannot be a dependent stimulus because it must have become an independent stimulus for all possible responses to be tried before it became permanent. A permanent 1st stimulus (independent) followed by any dependent or new stimulus could be in STM forming either a dependent or permanent stimulus.
Repeaters
A sequence can be made independent immediately when one of its parts repeats. This allows for reacting to a repeating pattern. Pre-S-Habit processing searches if any STM Level=1 stimulus repeats. It only needs to check Level=1 because if, for example, BM repeats after ABM is in STM then the B must have repeated first. If so it marks the highest level stimulus in STM as independent. This would be the ABM. The A would be dependent expecting a B. The B would be dependent expecting an M. The AB would be dependent expecting an M. The M would be independent expecting a B. The BM would be independent expecting a B. Then if this highest level stimulus (ABM) is non-permanent it puts it in LTM leaving STM empty. If the highest level stimulus is permanent it leaves it on STM. No, I think it also has to put this permanent stimulus in LTM. At which point the StoreStimulus routine will get rid of any duplicates that occur. This can't be done by STM processing because it deals with repeats at the S-Level=1. Storing in LTM deals with higher-level stimuli and does not store them if they are a repeat of the immediately previous stimulus. The B that repeated is not put into STM and it may or may not attract attention after pre-S-Habit processing.
Once this repeated sequence (let's assume it is the BM) has been explored and been changed to permanent should it be changed to dependent and permanent if it was always followed by the same repeated stimulus? Or should a stimulus that repeats have itself as its expected stimulus?
Next, pre-S-Habit processing searches to see if the last S-Level=1 stimulus in STM is expecting a particular stimulus. If so it checks to see if the expected stimulus has occurred. If it has then it gets combined with what is already on STM even if this expected stimulus would not have attracted attention! If the resulting highest level stimulus is an independent non-permanent stimulus it gets put on the S-List else it stays in STM. If the expected stimulus has not occurred then what is on STM could be changed to independent and put in LTM leaving STM empty. In the following situations the last S-Level=1 stimulus in STM has to wait until post-S-Habit processing for the attended to stimulus:
- If it is new and not expecting anything (RgtO = -1)
- If it is independent and permanent
When a new sequence of 2 stimuli is created its expected stimulus should not necessarily be the expectation of the 2nd stimulus. It should a -1 representing an unknown expected next stimulus.
Every stimulus, no matter what S-Level it is, goes through the following states.
- A new non-permanent stimulus with no expected next level 1 stimulus. RgtO = -1
- A non-permanent stimulus with one expected next level 1 stimulus. RgtO = x where x is the expected stimulus. This state can be skipped when a repeat occurs and the stimulus is made independent (state 3) from new (state 1).
- A non-permanent independent stimulus expecting multiple possible next level 1 stimuli. In this state all possible responses are tried.
- A permanent independent stimulus. No more responses are tried and multiple possible next level 1 stimuli are expected. RgtO = 0
Should an S-level=2 stimuli be expecting an S-level=1 stimulus? Maybe stimuli should be expecting only their own level next stimuli. This would be consistent with combining stimuli at the same level to create the next level up. Also (XX) it would allow the 2nd stimulus in a pair to be permanent and have many expectations while the pair may be dependent expecting only one possible next stimulus. Mind you, saying a high S-Level stimulus is expecting an S-Level=1 stimulus next is the same as it expecting the next high S-Level stimulus because only the next level 1 stimulus is needed to form the next high S-Level stimulus. This would not stop the situation in XX above from happening.
27th Feb, 2010 Repeating sequence
In STM I currently recognize a sequence once any one of the level-1 stimuli repeats such that ABAD creates the AB sequence when the second A occurs. However I believe the correct approach is to wait for a repeat of the same stimulus at any level that has not been separated by another stimulus at that level. Thus ABA would still be in STM when the D occurred. The D would then cause A to have two expected next stimuli and thus ABA would be the recognized sequence. But I have just realized this will not work for the sequence ABAB which would be represented in STM as A, B, AB, A, BA, ABA, B, AB, BAB etc. In this case there are no two stimuli at any level that repeat without any others between them.
1st March 2010 STM per Sense
Is it possible that each sense has its own STM? This would mean that before S-Habit matching and attention each sense's STM process would check for repeats, see if the same sense expected stimulus has occurred and combine it in its STM if it has. Non-permanent independent sequences, which include ones with unexpected next stimuli, would be added to the S-List. Then conscious and sub-conscious S and A-Habit execution would be done. And only then comes conscious attention. This is then followed by performing conscious STM processing using the attended to stimulus.
STM & Permanent stimuli
If STM is empty and a permanent stimulus is attended to then it should be put in STM hoping to form a sequence that is not permanent. But if STM has a stimulus in it (permanent or dependent (expecting X) or new) and a permanent stimulus X is attended to then STM should now contain the sequence. The fact that the 2nd stimulus is permanent and thus independent should not make the sequence independent.
2nd March, 2010 Overlapping sequences
If I have an STM for each sense then these will be producing sequences for conscious attention with overlapping content. The sequences will become conscious in the order that they are flushed from their STMs. Two flushed at the same time will form a P-Habit. Concentration on a particular sense would mean that the contents of its STM and the contents of the conscious STM are the same.
Object versus Attend to
The proper way of thinking about independent / discrete sensors is to think of each sensor as a different sense. That is how independent they are. The only way of combining two or more independent sensor readings is the same as P-Habits. Combine the sensor perceived objects at all the possible levels. At level 1 each object (O) is the combination of its Separation (S), Width (W) and Reading (R) pattern. At level 2 and higher the level-1 objects are combined into a tree. This identifies what the object is but not where it is. The location (A) of the object is the combination of Sense (Z), Separation (S) and Width (W) where it was found. At level 1 the separation and width is the same as used in identifying the object. At level 2 and higher the level-1 separations are combined into a tree and the level-1 widths are combined into a tree. Then the separation and width locations are combined at each level to indicate where to pay attention (A). The final experience is then a combination of an A and an O.
Thus given 2 independent sensors with symbolic readings on Sense #1 (Z1), sensor 1 produces the object O1 = S1 + W1 + R1 and sensor 2 produces O2 = S2 + W1 + R2 both level 1 objects. O1 is at attention location A1 = Z1 + S1 + W1 and O2 is at A2 = Z1 + S2 + W1. When the two level 1 objects are combined to produce the level 2 object O3 = O1 + O2. This object is at attention location A3 = Z1 + S3 + W3 where S3 = S1 + S2 and W3 = W1 + W2. O3 is NOT created by combining S3 + W3 + R3 where R3 would be R1 + R2.
Priming
When the readings are graduated all the reading objects are the same so changes in readings are used as the R1, R2 values. For the first stimulus value the change in reading from a zero value should be used just as the separation value for a level 1 object is the distance from the 0 position.
The where sense, separation and width that attracts attention is always the largest combination made up of the "what" objects that have changed from the previous frame. Each sense is maintaining two frames of information in order to determine those sensors that have changed their readings. However the senses do not create the change object between two sequential frames' readings. This is the job of STM.
When the sensors become dependent as in a graduated sense then an object's what separation becomes independent of its where separation. At level 1 the "what" separation must be zero because the object is position independent. But its "where" separation is relative to a zero location for the sensors. Also changes in width and separation can occur. I still have to think about how these changes will be used to identify the "what" object.
4th March, 2010 Patterns of Senses
P-Habits are parallel (happen at the same time) combinations of stimuli from multiple senses. The combination of senses involved forms a pattern just like the separation pattern. This I will call the sense pattern. The sense pattern must be combined with the separation pattern and width pattern to identify from where a stimulus (what object) comes. By using the sense pattern in this way I can unify the where object and remove the P-Habit discontinuity in the stimulus list.
6th March, 2010 Objects versus readings
Graduated sensors habituate. This means they stop responding when their input reading is constant. So they should only respond when there is a change in their input reading. Thus we would only become conscious of a stimulus when a sensor detects a change. A sensor could determine the length of time a reading occurs and produce this as part of the reading. This would mean that a graduated sensor reading an absolute value of 7 for 23 time units that detects a change in reading to 9 would produce the output of +2 and 23 as the duration. If the reading of 9 was constant for a duration of 11 time units and then the reading changed to 14 it would output +5 and 11 as the duration.
This is somewhat similar to the line detection / identification I use at level-1 for a graduated sense (dependent sensors). If a series of adjacent sensors have the same reading I produce a line with a reading they all have in common and a width. More specifically I produce a reading binon with a value of the symbol if it is a discrete reading and the change in reading if it is a graduated reading. Then I produce a level-1 width binon with value of the width. These then get combined to identify the object at level-1. Maybe I should produce a level-1 duration object with a time value and combine this with the reading object as well.
Everything is relative
Given graduated sensors only relative / change amounts are important in identifying the object. Absolute graduated readings are only useful for identifying where to pay attention (assuming we use the reading scale at all for attention). The challenge is to figure out how graduated sensor readings get converted into "what" object identifications such that they are equivalent to symbolic sensor readings. The answer so far is that the change amount detected by a graduated sensor is equivalent to a discrete value detected by a symbolic sensor. If so then a series of symbolic values such as A, B, C would be equivalent to a series of changes such as +1, -3, and +8. A series of A, A, A would be equivalent to a series of +1, +1, +1. But this is not the interpretation being used for the symbolic values. When a sensor detects the 'B' following the 'A' it says the object has changed and I now recognize it as a B. When a sensor detects two Bs in a row it is saying the object has not changed and it is still a B. In this second situation the sensor has been polled as opposed to it detecting a change. When a sensor produces a -3 following the +1 it says the reading has changed by the amount +3. When a sensor produces two +1s in a row it is saying the object has changed in both instances.
Maybe one unifying approach would be to treat discrete values and graduated readings similarly except when it comes to the change amount for graduated readings. This would mean each sensor would not produce a stimulus until it detected a change. It would then provide the value and the duration. But the symbolic reading has a different meaning than the change in reading. The symbolic reading says I know what the object is already. The change in reading says I know what it is relative to another reading. For graduated sensors symbolic identification does not take place until level-2 when a separation, width, reading change pattern can be used.
According to my definition, an object, which symbolic reading sensors detect, is identified because its parts all change in unison. This means that we need at least two parts, which could be two readings. These two parts have a relative reading and this relative / ratio stays the same from one time slice to the next. Then the object gets even more reliably identified if the relative size / width of the two parts stay the same from the 1st to second time slice. And even more reliable if their separation ratio changes in unison. Then if we add duration we can say the relative duration between them changing is constant as well. Therefore we need graduated readings from two different sensors and two time slices to identify an object at the same level of identification given by a symbolic reading.
7th March, 2010 Object Identification
I've decided that I should capture the object information separate from the reading. Thus a single graduated reading sensor is always detecting the same object but with various readings over time. A single symbolic reading sensor is detecting various objects but always with the same reading. This means that the 'what' object that a sensor detects consists of the primitive object O, with a reading R, at sensor location S and a width W =1. Also its duration D is 1. The 'where' object for this sensor reading would be on sense Z, at location S, at width W and at reading R. If time is to be included then for duration D.
Given 2 symbolic sensor readings B and C on sensors 2 and 4 the following information would be used at level 1.
| Sense Z or Object O | Separation S | Width W | Reading R | Duration D | |
| Where | 1 | 2 | 1 | 0 | 1 |
| What | B | 2 | 1 | 0 | 1 |
| Where | 1 | 4 | 1 | 0 | 1 |
| What | C | 4 | 1 | 0 | 1 |
In the 'what' information the reading is the same but the object is different. The Where information is the value of the level-1 where patterns.
Given 2 graduated sensor readings 3 and 7 on sensors 2 and 4 the following information would be used at level 1.
| Sense Z or Object O | Separation S | Width W | Reading R | Duration D | |
| Where | 1 | 2 | 1 | 3 | 1 |
| What | 0 | 2 | 1 | 3 | 1 |
| Where | 1 | 4 | 1 | 7 | 1 |
| What | 0 | 4 | 1 | 7 | 1 |
In the 'what' information the object is the same but the readings are different. The Where information is the value of the level-1 where patterns.
If the sense is discrete / independent sensors and we consider the two symbolic readings B and C then at level-2 a pair of sensor 'what' objects are combined. Given the above example the level-2 information would be:
| Sense Z or Object O |
Separation S |
Width W |
Reading R |
Duration D |
Binon B |
|
| Where | 1 (z) | 2 (s) | 1(w) | 0 (r) | 1 (d) | |
| What | B | 2 | 1 | 0 | 1 | 23 |
| Where | 1 (z) | 4 (s) | 1(w) | 0 (r) | 1 (d) | |
| What | C | 4 | 1 | 0 | 1 | 24 |
| Where | 1 (0,0) | 2 (0,2) | 1 (0,0) | 0 (0,0) | 1 (0,0) | |
| What | - | - | - | - | - | 49 (23,24) |
The 'where' patterns are relative combinations with an absolute starting value. The 'what' information is the aggregation of the two parts. Binon B23 is the combination of S2, W1, R0, D1, and O = B. The separation / sensor location is necessary to uniquely identify what it is so that a B on sensor 2 is different from a B on sensor 4. I will also need the sense in identifying it so that a B on Sense 1 at sensor 2 is different from a B on Sense 2 at sensor 2. The binon B49 is the combination of B23 and B24. That is a unique 'what' it is. The combination of the 'where' information indicates where it is.
24th Mar 2010 Basic stimuli
While in Reston on March 8th and 9th I devised the idea that the lowest level-1 what object should be the pair of reading values or symbols made up of the previous and current readings. If they are values then the difference is kept in the 'what' object. The 1st ever reading will use the zero reading as the previous value or symbol. For symbolic readings this means that the dependency on the previous stimulus is kept in the lowest level. The 1st A is stored as 0, A and when A repeats it will be X, A where X is not the 0 stimulus. This is why STM produces the string of stimuli up to but not including the 'A' when it repeats. The 'A' has become independent on its 'previous' side. STM functionality is now down at level-1 as though each sensor is independent and has its own STM.
Sense of Time
For a sense of time I need timing and duration objects which will always be graduated like separation and width. For non-permanent stimuli the duration is always 1. For permanent stimuli the duration will have a value >= 1. Two duration objects can be combined to form a duration pattern which is a relative pattern like width patterns and times can be combined to form a timing pattern just like separation. But do we recognize time patterns? Maybe not because each change causes a new time interval and therefore we cannot form gaps in time. However we have a sense of the time between two events that have many events between them.
Binon representation
Is it now necessary to store values in the binons above level 1? The level-1 binons contain the relative values of readings, widths, etc. and level-2 and higher just form combinations of these. The sensors maintain the absolute values of the last reading to create the relative Level-1 binons. The Where information that makes up the experience must still retain a Sense, Sensor, etc. absolute location for where to pay attention.
STM
An object remains dependent as long as it has only one previous and one next expected object. The symbolic pair at level-1 stores its previous object as the 1st of the two values so this can be used to keep information about its previous dependency. A value reading is stored at level-1 as a difference in value and will always have a zero as its 1st value. This means that its dependence is only captured at level-2. When I try to find an object in the binon tree it should be able to return information about its left and right dependency from the number of occurrences of it as the left and/or right part of binons. As soon as an object becomes independent either on its left or right then it starts to be explored. The longest series / pattern with expected changes between the parts does not get sub-divided into its parts for exploration purposes. The whole longest series /pattern is the smallest unit of exploration.
Object Identification
Surely the sense also forms part of the 'what' identification of the object. This is necessary so that two objects on different senses are not the same object just because they have the same separation, width, readings etc. When you pay attention is the 'what' information sufficient to direct the attention?
Ratio versus difference
Since an object is made up of two parts which change in unison, I've been trying to sort out when to use a pattern of ratios that stays constant over time and when to use a pattern of differences that stays constant over time. When measuring a reading that could be for example brightness, the values are from zero to a very large order of magnitude. Two parts, each with its own brightness have a relative brightness determined using subtraction. Then when the overall brightness changes the pattern of differences in brightness stays the same. Thus relative brightness is obtained from subtraction and the change (added or subtracted) in brightness is the same for each part. This applies to any reading that measures the parts. This includes position, pressure, distance-away, weight (change in gravity), temperature, volume (audio) and absolute clock time. However as soon as two of these readings are required for an object to obtain a range of values then the pattern of the ratio of the ranges must stay constant. This means division or multiplication must be used for the pattern. Width is a good example because each part has a width and a range of positions determines it. The ratio of the two widths forms a pattern that stays the same as the overall object's width changes. This also applies to the separation between two parts, which is a range of positions. Time between two events is a range in time and two such ranges form a timing pattern. A timing pattern gets stretched out like separation if it is to retain its profile. The same applies to a pattern of durations.
However let us consider a 360-degree sense which maps the angle onto a sensor position. This works just like any position, when a range is formed using the difference in any two angles we end up with separation and width patterns based on ratios not differences. But now consider frequency / pitch. The human ear maps this to a linear array of sensors. We do not have the ability to notice a difference in pitch of 55 hertz between two notes at any given frequencies. The difference between two piano-keys at frequencies of 55 and 110 hertz sounds the same to us as the difference between two piano-keys at 110 and 220 Hertz. Thus we recognize ratios of frequencies not differences. This is because they map to sensor position 13, 25 and 37 rather than to 13, 25 and 49. These sensor numbers are the keys on a piano for these frequencies. And sensor positions are subtracted from each other to provide separations and widths, which are ranges.
Thus the following needs to be done:
Width create pattern based on Ratios it's Graduated, if dependent sensors
Separation create pattern based on Ratios it's Graduated, if dependent sensors
Reading create pattern based on Difference it's Graduated
Object create pattern based on Absolutes it's Discrete
Sense create pattern based on Absolutes it's Discrete
Timing create pattern based on Ratios it's Graduated
Duration create pattern based on Ratios it's Graduated
But what to create first? First must have a start-up frame with all zeros. One object per sense with width = number of sensors at position / separation zero and brightness zero, or one of these objects per sensor if independent sensors. Second must create the level-1 objects from the 1st real frame of readings. Each object needs a sense, width, separation, reading, and object pattern. The reading should be the difference / change in reading on the sensor from the previous frame rather than the absolute reading. Then the across sensor reading pattern is a pattern of reading changes / differences. This was part of 2nd March thoughts.
25th Mar, 2010 Intra-Sense Stimuli
I'm trying to finish the implementation of the idea from 4th March. However it is challenging to represent all sense combinations of all level objects from various senses. One sense might produce a level 4 object as its highest level object and another sense only produce a level 2 object as its highest. I was thinking the sense patterns were going to be the NumSenses^2 -1 possible sense combinations but it does not appear to be so. The question is how do the patterns in general get used to pay attention? And how does similarity work using these patterns? The idea of using patterns is to describe a sensor position independent, absolute reading independent, absolute time independent, reflection and negative independent object. However the senses are absolute and we don't want a sense independent pattern. Same with position if the sensors are independent - the widths are all 1 and there are NumSensors^2-1 combinations of sensors.
I think I have to combine all the stimuli from the object tree from one sense with all the stimuli from the object tree from another sense and disregard the level at which the stimuli are at in each sense. This will produce sense level-2 combinations. Then these need combining at higher sense levels provided they share a common part.
26th March 2010 Relative values
Even if I have independent sensors on a sense they are all reading the same sensory information. Thus the reading of one can be compared with the reading of another when forming patterns of them. This means the readings are relative across independent sensors on the same sense. Thus when two sensors are combined at level 2 the difference in reading values must be retained and not the absolute reading. But should I form sequential difference in reading on a sensor before or after combining sensors and capturing their reading difference in the same frame?
27th March 2010 What is stored?
After thinking about orientation and reflection, I realised these properties need to form part of the object as recorded in the experience in LTM. One can also notice the change in these properties. This table tries to sort out what properties form part of an object, for which ones change can be detected and which get kept in LTM. An object has properties that are fundamental to it and independent of sensor position (graduated sense), sensor reading (graduated reading) and time. These object properties are listed in column A. We store in LTM the objects that we have experienced and the reactions made associated with them. The properties of objects that are stored in LTM are listed in column B. We are able to detect changes / sequences in properties over time and these changes can be reacted to as though they were objects themselves. These changes must be kept in LTM as part of the experience. These detectable changes are listed in column C. Column D is the technique used to process / represent the property changes that are listed in column C.
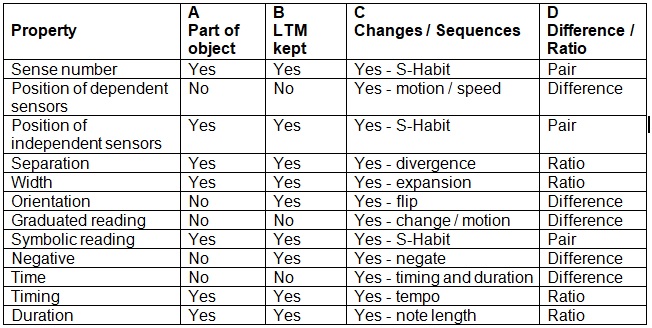
Sensor graduated readings are any measurement made by a sensor of any of the following dimensions:
- Brightness (Intensity of electromagnetic radiation (EMR))
- Volume (audio)
- Frequency (audio and EMR)
- Distance away
- Position (x, y or z)
- Angle (rotational, latitude, longitude, azimuth, elevation, yaw, roll, and pitch)
- Weight
- Tension
- Torque
- Temperature
- Pressure
28th March 2010 Level independence (Levels of Complexity)
On the 4th August 2009 and again on 23rd Nov 2009 I mentioned the need for all patterns to be level independent. This is a key concept because it means that any two parts, no matter how complex the parts are, must be able to match the level-2 pattern comprised of the difference / ratio between two parts. Differences / ratios are then the concepts / properties that parts have. If we considered two complex parts with a particular brightness they would each have an internal brightness pattern. But the relative brightness between them would also match a level-2 brightness pattern, which is a brightness difference. But what brightness reading is used as the particular brightness for the two parts. If one were considering a position difference then one would want to use the centre of gravity position. Same with brightness, one would want to use the centre of brightness reading. Do sensors produce averages of brightness over ever-larger widths for this purpose? How do higher level complex parts retain an average brightness reading to form a simple pattern?
An algorithm that would continue to produce an average brightness that could also be used to calculate the differences is as follows. [The problems with this approach are at the end of the paragraph]. Given adjacent sensor readings of 3, 7, 1, 2, 2 and 9 we want the adjacent differences to be 4, -6, 1, 0 and 7. We also want the adjacent differences between the 1, 2 and the 2, 9 to be 4. This is calculated by taking the differences between the average values of 1, 2, which 1.5 is and 2, 9, which is 5.5. (5.5 - 1.5) = 4. The approach that saves having to store real numbers and also saves from having to accumulate larger and larger totals and dividing by the total number of sensors involved is to always represent the value times 2. To calculate the difference, subtract the values and divide by two. To get the value of the pair, add the two part values and divide by 2. Thus the sensor readings become 6, 14, 2, 4, 4 and 18. The differences are now (14-6)/2 = 4, (2-14)/2 = -6, (4-2)/2 = 1, (4-4)/2 = 0, and (18-4)/2 = 7. The new values for the pairs formed at the next level are (6+14)/2 = 10, (14+2)/2 = 8, (2+4)/2 = 3, (4+4)/2 = 4 and (4+18)/2 = 11. Now the difference of 4 between what was originally the 1, 2 part and the 2, 9 part is (11-3)/2 = 4. Since this is a local algorithm it can be repeated at any level and can be done between any two parts even if they are at different levels of complexity. Complexity is the number of levels of subparts they contain. 1st problem is that one of the 2nd level values is an odd number. 2nd problem is this would work fine at level 2 complexity because the two parts do not contain any common parts. For more complex levels there are always shared parts. This presents a problem for this algorithm. This algorithm works fine for differences but what about ratio patterns that also must be recognized independent of the level of the parts.
To make this work properly I would have to make additional combinations of parts that are not covered in the current 3+ levels that use overlapping common parts. At level B I would produce the same pairs I currently produce from level A raw stimuli. At Level C I would create current level 3s from these pairs plus any combinations of level A and B parts. Then at Level D I would combine any two objects from level A, B or C. Only in this way can higher level pairs be made from parts at any previous level.
29th March 2010 Level combinations
Maybe the pairs (level-B 2somes) and level-A stimuli (1somes) are not combined. Maybe pairs are combined with overlaps and non-overlapping pairs, possibly with gaps are combined for level C. Level C would contain 3somes containing overlaps and 4somes of two pairs. Then level C's are combined with overlaps and non-overlapping pairs, possibly with gaps, for level D. Level D would contain
- 4somes containing overlaps of two 3somes,
- 6somes containing overlapping 4somes,
- 6somes of two 3somes non-overlapping,
- 7somes by combining a 3some and a 4some and
- 8somes of two 4somes.
So the previous level objects are combined either with overlaps or separated with possible gaps. Then any level is made up of combinations of the previous level only.
Recognition principles
This is a summarisation of the recognition principles to date:
- The two parts of an object change in unison. They have a specific interdependency that does not change over time.
- We are attracted to the biggest combination of parts that change.
- For reaction purposes we use the largest / longest objects in which the parts are interdependent, i.e. other possible combinations of the parts have yet to be experienced.
- A sequence of two objects also forms an object.
Priming - Initial values
When a sense is turned off all the sensors produce a reading of zero. When it is turned on the sensors start producing reading values. The changes from zero readings on this first frame are anomalies of the initiation of the sense. Rather than producing changes from zero to these values for the first frame I think it would be better to assume the values have not changed, as though the previous frame had the same values.
Kept in LTM
The senses and sensors keep the absolute readings, graduated sensor positions and time stamps for the stimuli in the two frames. None of these three pieces of information make it into LTM. However the changes in them do. Changes in reading from a single sensor combined with the simple sensor object are the first objects to be formed. For sensors with symbolic readings the change of either 0 or 1 combined with the simple sensor object, which is based on the symbol, are the first to be formed. Relative dependent sensor position (separation) of these objects then forms the next level of object. These are combined based on the ones that all changed by the same amount (graduated reading changes or symbolic changes) because that means they are all parts of the same object. Their interdependency did not change. Their interdependency is their relative changes in readings, which are the reading change pattern [corrected below] and the symbolic pattern. They are sensor position independent. If the sensors are independent then the sensor object is combined with the sensor number to make it unique. These can still be combined across sensors based on the ones that all changed their readings by the same amount because they all measure the same type of information because they are all on the same sense. However no motion is possible because they are assigned sensor numbers.
When compound objects are formed from one frame they must retain a position while in the frame so these values can be used when they are combined to form the next level of complexity objects. For position this can be the position of the left part of any pair. Separation will always be the difference between these values. And the separation ratio of the two parts of an object will be the same for the object at different sizes. However the graduated reading values do not need to be retained [corrected below]. What is in each object is it's change in reading and the pattern of these relative reading changes that gets combined as a pattern to help identify the object. For symbolic readings the pattern will be the combination of simple sensor objects (the symbols).
Widths
If I use the new levels to combine the objects do I still need width as a specific property or is it taken care of in certain separation patterns? If I had a 2-part object with parts adjacent and the same raw reading value and symbolic object the reading changes would both be the same. The reading change pattern would have a difference of zero between the two reading changes because the raw readings and symbolic object would be the same. I just realized that the sequential time change in reading starts to form the time based pattern. The reading pattern that is between the sensors cannot be the differences in these changes. It must be the differences in the raw readings and symbolic objects. Thus the raw reading must stay with the inter sensor reading changes so that changes in readings between compound objects can also be determined. However it does not need to be the centre of gravity reading just as the position does not need to be the centre of gravity position. It can be the reading of the left part of the pair. This now allows a 2-part object with the parts adjacent and the same raw reading value and symbolic object to have a separation of 1 and a reading difference of zero. If two of these were combined using the overlapping piece it would form an object at level-3 with a separation of 1 and reading difference of zero. The level is now representing the width. But then I have to combine an object at level C with an object at level A to form the pattern XXXoooF where the XXX is at level 3 = C and F is at level 1 = A.
30th March 2010 Object identification
A generic object is independent of position, brightness and size. To do this only relative values of these three measures must be maintained in generic objects so they can be recognized when they occur again. If a generic object only consists of two parts there can only be one value each for the differences in position, brightness and size (level). The parts of a generic object have these three dependencies and they are constant for a given generic object. So now how does this approach recognize a two-line pattern which expands or contracts? For example, XXY is the same generic object as XXXXYY but just with a different absolute level / width value. XX has absolute values of Reading = X, Position = 1 and Level = 2. Its difference values are Contrast = 0, Separation = 1 and Level difference = 0 since its two parts are at the same level. XXX which consists of two XXs overlapping has absolute values of Reading = X, Position = 1 and Level = 3. Its difference values are Contrast = 0, Separation = 1 and Level difference = 0. XXXX will just differ in its absolute level value and be the same generic object. XXY is the combination of XX and Y. The table below captures the absolute and difference values for all these objects.
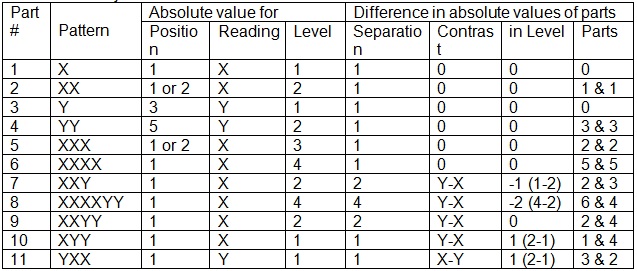
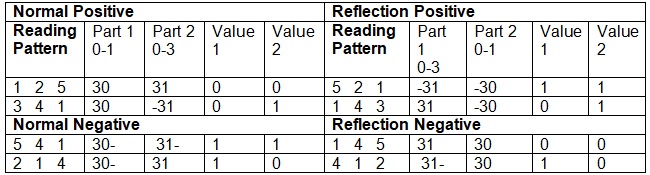
This shows that for the generic object to be recognized independent of overall size the ratio of the Separation to Level difference must remain constant.
Reflection (opposite orientation) and negatives must also be recognized as the same generic object. This means that the absolute values of negative difference and positive difference must be used for comparison. The generic objects only need to keep the positive values
So to uniquely identify a level-1 generic object I need its Sense, Separation, Width (Level) ratio, Contrast, and Structure combined.
31st March 2010 Minimum Object
The object recognition principle that we do not subdivide an object into its parts for reaction purposes if they only have the one interdependency / interpretation is critical for combining parts. The first frame we recognize will become one large interdependent object because none of the interdependencies have any other interpretations. However if the priming frame is all zeroes then all the changes in intensity will be independent (start new sequences) because zero can be followed by a variety of values. I would expect that all the changes in intensity would become independent very soon after the beginning of life due to the variety of changes that can occur. So too will the contrasts between sensors. However at some higher more complex level objects should occur in which there is only one interdependency interpretation. At this point a complex object has been recognized. I will call it an IDed object. Once one of these IDed objects has been recognized then all the subparts are locked into it and do not contribute to any other object. But once the many IDed objects have been found and all the sensors covered then the IDed objects are combined to create the entire scene from recognizable parts.
1st April 2010 Symbolic = IDed object
A symbolic object is already an IDed object. It only has one possible interpretation. After this the recognition processing is all about grouping them into clusters such that they all change at the same time and retain their interdependencies. The change is either yes or no at this level. Amongst the ones that have changed they are combined into the largest groups that have been observed before they are identifiable. The same would take place amongst the ones that have not changed. If two symbolic stimuli on independent sensors change at the same time then they either are recognized as a known possible pair or as a unique IDed pair. If there are only these two sensors then the pair is what attracts attention because they both changed. Let's study a pair such as sensor numbers 1 and 2 and stimuli on 1 of A and B and on 2 of C and D.
The sequence to study is:
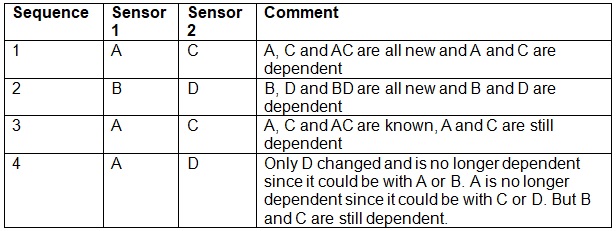
Two stimuli are dependent if they have only one possible interpretation. At least one of the parts has been found only with the other. An example is A C after step 4. A is an independent part and has various relationships. But C is still dependent because it only has the one relationship with A. Thus the 'A C' pair is a recognizable IDed stimulus. However A D is a pair of independent stimuli and though it can be recognized as a pair the parts are the IDed objects and are reacted to independently. It is only if the 'A D' pair has a unique relationship with a third dependent object that it becomes a part of an IDed object that is symbolic. In this case A has a unique relationship with the third object and D has a unique relationship with the third object.
For graduated reading stimuli they must also be combined into these largest groups that have been perceived before. Except in this case it is all the ones that have a change in intensity of 1 that are grouped. Then all the ones that have a change in intensity of 2 that are grouped and on up the amount of change dimension. If one stimulus has a change of 1 and another a change of 2 then they are independent.
Order of combinations
For symbolic stimuli (S) they need to be first combined with their sense (Z) to make them unique across senses. I will call this combination ZS. The contrast between two sensors should be; zero if they have the same ZS symbol and 1 if they are different. Then if the sensors are independent the ZSs should be combined with the sensor number so they are unique per sensor. For graduated stimuli even though the nature of the value being measured is sense dependent the change in reading is sense independent. An increase in volume can be related to an increase in pressure or brightness. However are the magnitudes of the changes comparable or just the direction / orientation of them? I think the magnitude is comparable because we easily correlate height of a note on a music score with the position on the keyboard and the pitch of the note.
Orientation
Absolute orientation of contrast or symbolic structure, relative width and separation is probably not kept in LTM. However relative orientation will need to be because if a subpart has a different orientation the whole is a different object. And it is relative orientations of the parts that we remember for a generic object. Read 5th Nov & 10th Nov 2009.
2nd April 2010 Orientation of change
A change in reading has an orientation in the time dimension. The reading either increases or it decreases. The relative orientation from one change in reading to the next change must be kept as part of the generic change objects.
3rd April 2010 Stimulus independence
Using the same table as on 1st April 2010 but with a little more complexity helps to clarify how the idea of dependent and independent stimuli should work. We consider 4 independent sensors reading a sequence of symbolic values.
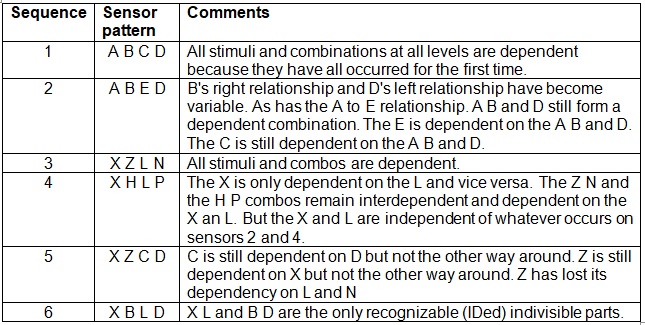
Given this progression of interdependency information how are the stimuli combined at greater levels to form IDed objects? Repeating the rules that; "Two stimuli are dependent if they have only one possible interpretation. At least one of the parts has been found only with the other." provides a useful starting point. We don't need a two way interdependency to recognize a pair. Thus in the example above, X Z is recognized because Z has a left dependency on X but not vice versa. C and D are similar. Once such IDed pairs have been found, if any, 3somes are formed using these pairs and other single stimuli. The parts of the pairs are not combined with other stimuli because the pair is indivisible. Pairs may be combined provided they share a common part. These 3somes should already be IDed. Combinations of an IDed pair and an independent stimulus should never be IDable because the independent stimulus gives the combo independence. Pairs of pairs however can still be dependent.
4th April 2010 Representing Objects
The principle is fairly clear. The challenge now is to devise a data structure to represent this information and make it easy to use and process. Or is it possible this feature will fall out naturally from a simpler process. The data structure that might directly address the requirement is to have two dependency flags on every pair of stimuli. These would start out as dependent and change to independent whenever the stimulus in this position in this relationship pair has more than one other part. It's a property of a pair made up of two particular positions with a particular left or right part. But maybe using the "only one possible interpretation" principle will accomplish the same result. I could generate all possible interpretations and wherever there is only one then that one gets used. How I recognize the just one I don't know yet. Maybe when given a pair to find the binon for it also counts if it comes across any other occurrences of the parts in this separation relationship. This would mean continuing to search to the end of the list of binons if a second pair is not found even after the one being identified has been found.
5th April 2010 Sense identification
At the end of 30th March and on the 1st April 'Order of Combination' I pointed out the need to combine the sense of a stimulus with its symbolic value as soon as possible before processing separation, width differences and contrast. But this would not be done on changes in readings for non-symbolic stimuli. On the 4th March I introduced the idea of combining objects across senses using a sense pattern. This latter idea takes place after the IDed objects. The human brain combines sense with stimulus at the earliest stage because sensors and the part of the cortex that process their stimuli are physically dedicated to the senses. So how do we recognize positive and negative change independent of sense? The cortex must be able to recognize change as well as the sensors. This means that any neuron can detect change. Which is true since they have a time based decay pattern. It is also true for binons because they are in LTM, parts of S-Habits and have expectations about what is next and that is time based. Is there value in the 4th March idea to create sense patterns that are not buried in the combinations of IDed objects which have been sense associated? Does the sense pattern provide a 'where' combination, not stored in LTM with the IDed what object? Does it make it easier to pay attention to a certain combination of senses? The same questions can be asked of sensor positions for independent / discrete sensors. Sensor positions need to be combined with the symbolic readings as soon as possible after the sense has been combined with them if the sensors are independent / discrete. Width and separation have no meaning for independent sensors.
Symbolic and graduated readings
But my new representation includes both a symbolic and a change in graduated reading as part of every stimulus. So the sense can always be combined with the symbolic part.
6th April 2010 Representing Objects
On 4th April I suggested a simple process might give the same effect as I have documented on 3rd April. This simple process might be just to return information as to whether the combination is a new one or an already familiar one. If it is a familiar one then flag the two parts as not to be used in any combination that would produce a novel combination. They could still be used in a familiar / known combination. If it is an unfamiliar combination then the parts are free to be combined in other ways in an attempt to come up with familiar combinations. This is a similar strategy to 24th Aug and 28th Aug 2008.
7th April 2010 Representing Orientation
Orientation is needed for separation to get reflections and for intensity to get reflections and negatives. Width has an orientation as does changes in time of a reading. Each frame of experience must retain the absolute orientations but the generic objects must keep relative orientations. Let's analyse an example using graduated reading values and a graduated sense whose orientations are negatives and reflections.
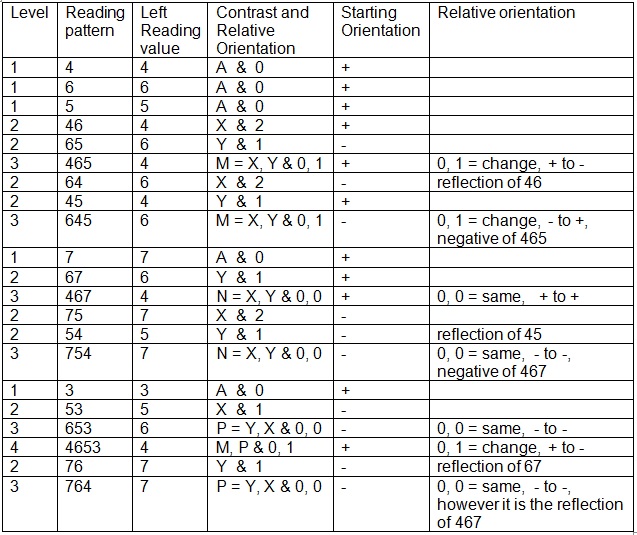
The contrast and relative orientation object can keep both pieces of information. At level 2, the values are the difference in reading giving relative brightness. At level 3, the contrast pattern is in the pair of objects and the values are being used to indicate the change in orientation from the left stimulus. The Left Reading value can be made positive or negative to indicate the starting orientation. The reflections at level 2 are the same as contrasts but they deviate at level 3. It would have been proper to identify P as the reflection of N.
Representing Reflections
A modified structure should work for reflections and negatives.
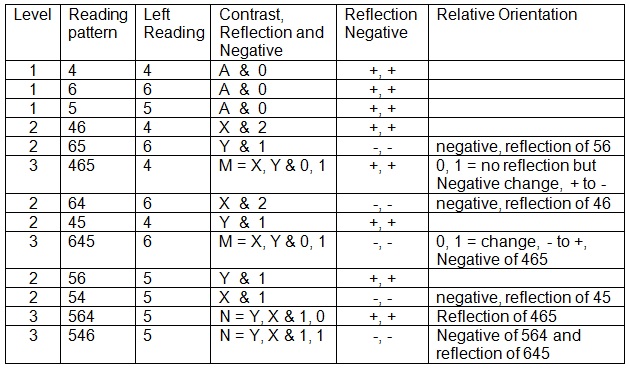
But it does not use M for all four level 3 generic objects. It might be best to represent relative negativity and relative reflection as their own objects rather than use the value parts of a binon.
Representing Separation
A reflection may have the same intensity readings in the other order but this does not capture the separations in the other order or the widths in the other order. All these properties arise from having a graduated sense of dependent sensors.
9th April 2010 Stimulus properties
The following table summarises the properties that apply to stimuli depending on whether they come from a graduated sense or not (sensor dependency) and from graduated readings or not (symbolic or values). It is for stimuli that are very high in level and are comprised of two parts from the level below.
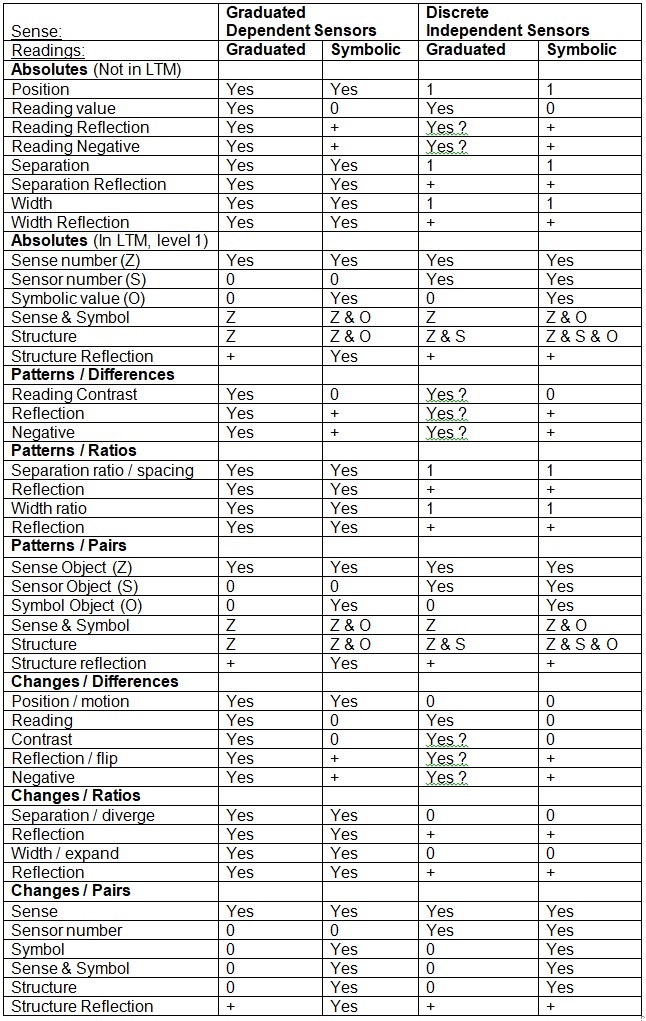
A generic / IDed object from a graduated sense using graduated readings needs to at least have a Sense, a reading contrast, reflection and negative pattern, a separation ratio and reflection, and a width ratio and reflection. However a generic object may be one that has a certain combination of parts independent of their relative separation, contrast and width. But that is because the parts are generic / IDed. So the combination acts like a combination of symbolic objects. Can we get away with just a certain contrast pattern and have a generic object? No, shape, which consists of separation and width, plays an important part in identifying a generic object. The ratio of separation to width must also remain constant.
11th April 2010 Object Identification
The IDed object is a combination of the Structure, Contrast, Separation and Width patterns. The contrast-pattern substitutes for the symbolic object structure if readings are graduated. The separation and width patterns substitute for the sensor pattern when the sense is graduated.
Human body
Supposedly the human body has approximately 100 joints, 600 muscles but a billion receptors / sensors. A lot more input that output devices.
14th April 2010 Separation and Width
After finding it so difficult to represent and process width ratios last night I realized this morning that width and separation are one and the same concept. I have previously mentioned that the expansion and contraction of the width pattern and separation pattern must remain in synchronisation if the same object is involved. This should have clued me in. However the idea is that width is the separation between the edges and my current separation pattern is just using the left edge. So what I have to do is recognize the edges and then perform separation pattern recognition on them. Edges are found at level 2 processing when a pair of sensors are processed and found to be of different value (symbolic or graduated).
But after trying to implement this idea I have run into complexity issues. At level 2 I combine lines of width 1 with gaps of width 1 or greater. This is inconsistent because the right edge of a line is the left edge of a gap or the next line. I need to treat the gaps as though they were special lines. But if I am going to represent gaps with width 1 or greater I should do the same for lines. How can I represent a gap as a line of null symbols of zero readings? These values are reserved for the concept of the sensor being inactive, reading nothing. I think this will work as also meaning that this part of the pattern contains no part of the object i.e. a gap. So at level 1 I need to produce all the lines of width 1 or greater. At level 2 I would produce all the line and line pairs and all the line & gap or gap & line pairs. At level 3 I would produce all the combos of line pairs, line & gap & line and gap & line & gap combos. I would need to produce the gap & line & gap combos so I can form higher level ones with just lines on the outsides and still retain the separation ratio which includes gap widths / separations. However when it comes to moves and generic objects etc. only combos with lines on the outside will be relevant.
18th April 2010 Widths and Ratios
I think I finally have a foolproof way of representing width ratios. The two objects in a particular order represent the ratio of the two parts. Then the values are used to represent the reflection status of the two parts. In the following example part 30 and 31 represent the ratios 1/2 and 2/5 respectively. A minus sign represents a reflection of that object also captured in the Values.
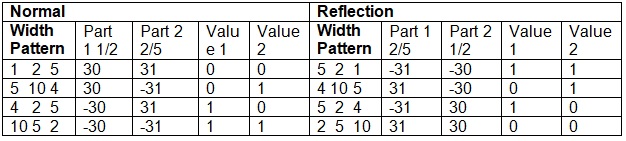
At level 1 all the widths are the same relative width pattern of 1. At level 2 all the different ratios are captured in the values and the level 2 objects represent these ratios. Then at level 3 and higher the pair of parts at the previous level plus the reflection flags in the values is sufficient to represent the relative width patterns.
However the problem occurs with the level 2 ratio of 1 to 1 when used at level 3 as a part. Its reflection is the same object. For example if part 41 and 42 are the 1/1 and 1/3 relative width ratios then the width pattern 113 has two possible interpretations. It could be the normal 41 42 with values 0 and 0 or the 1st part could be a reflection -41 42 with values 1 and 0. The 1/1 has to be recognized and only the 41 42 0 and 0 interpretation made. The same problem occurs with the 1113 width pattern and ones with longer series of repeating width values. It looks like the solution is to map any repetition like this onto the lowest level 1 to 1 width pattern, test for this and only produce the one interpretation.
But on further experimentation it appears the problem occurs wherever there is a symmetric subpart. 1121 has a reflection of 1211. The '121' is the symmetric subpart, which causes problems if not given the same reflection status as the other subpart. This then works but I am still not sure about recognizing a repetition of a width ratio as the same object. This results in the width patterns of 1, 11, 111, 1111, etc. all being the same width pattern object. But also 12, 124, 1248, etc. all map onto the same width pattern. This is analogous to a constant motion in the first case and an unchanging acceleration in the second.
Representing Negatives
If I use a similar technique to represent contrast how do I capture the negative status of a contrast pattern? The use of a similar table to the one above shows that half the possibilities are the negatives.
21st April 2010 Contrast Reflections and Negatives
I got negative recognition working today. See Objects1 software for solution.
23rd April 2010 Familiar and Novel
I've been using an algorithm that combines parts according to the familiarity or novelty of the resulting object to highlight what is new at each level. The logic is, on the first pass through the source parts, if a combination is familiar then, keep it, mark it familiar and mark the source parts used. On the second pass just combine the unused parts and they are marked new. A simpler algorithm would be to combine only the familiar parts from the source level and mark the results either familiar or new. Then combine the new parts from the source level and mark the results new, which they must be because the parts are new.
Attracting attention
The largest new result is the one that attracts attention because it contains all the parts that are new based on experience. The other rule for attracting attention has been the largest combination of parts that have all changed (are new) from the previous frame. The first definition is based on LTM familiarity while the second is based on sensor familiarity. The second definition provides the first level of sequential familiarity. This must be followed by LTM familiarity. Then STM is also involved in sequential familiarity based on LTM sequences. What we have is instantaneous / parallel novelty and sequential novelty. Given a frame of symbolic stimuli instantaneous familiarity / novelty is obtained based on LTM experience. However the subset of sensors that have not changed (are not new, are familiar) from the previous frame must all contain familiar stimuli. Thus the changed sensor stimuli are the candidates to form new combinations.
Independent sensors
If I have independent sensors on one sense then the sensors are truly independent of each other. In the case of graduated readings they are each measuring a different object. Reflections of reading patterns across two sensors do not make sense. The patterns formed by combining two or more sensors are unique based on those sensors and the stimuli perceived. Even though graduated sensors are all reading the same sense information a reading on one sensor is not the same as the reading on another even though it may be the same value. Similarly a change in graduated reading on one sensor cannot be related to the same change of reading on another sensor.
However, is it important to detect any dependency between sensors that are meant to be independent? If so can this dependency be noticed in the sequences of changes that occur rather than the inter-sensor relationships? For example sensor A and B have values 3 and 4 respectively. They change to values of 6 and 7. The relationship of B's value with A's (+1) would not be relevant. The relationship that A's value and B's value both increased by 3 would be irrelevant. What would be relevant is that a 3,4 is followed by a 6,7 sensor value pattern. I believe so. This should remove the Yes?'s that appear in my April 9th table. And 26th March is wrong.
To represent graduated readings on independent sensors I cannot combine the sense and sensor with the reading because the reading is not an object. What I need to do is combine the sense with the change in reading object and then can combine this with the sensor to give a unique sensor dependent experience. The contrast object must always be the same because the sensors are independent.
26th April 2010 STM per Sense
I believe my idea of an unconscious STM per sense from 1st March is correct. Each STM would form and keep sequences of stimuli from a sense. It would form sequences that are familiar - expected changes based on LTM experiences and these would not attract attention. This is the same idea for familiar combinations of lines from an array of sensors. Repeated stimuli would be combined into a single stimulus with a duration equivalent to a width. The longest familiar sequences would be formed. Then any sequence which is followed by an unexpected stimulus or a novel stimulus which has no expected stimulus would become interesting / novel. Effectively each sense is executing all its sense specific S-Habits. When all the currently active S-Habits fail because they cannot explain the current stimulus or any part thereof, the contents of the STM become interesting. The sequences would contain the time based relative changes (not the absolute values) in reading, position, width, reflection, and negatives for any specific objects that continue from one frame to another. It would be the symbolic object sequence with all of these relative changes set to zero for symbolic readings. The sequences would be available for directed attention but otherwise would form and be removed from STM when they complete. The current stimulus or part thereof which is not explained by the active S-Habits attracts attention.
Conscious STM however works slightly differently since it has to accept the first ever longest sequence made up of stimuli that have no next expected stimulus as the expected one. Sense based STM then continues to recognize this sequence subconsciously. However the first occurrence of an unexpected stimulus will cause the STM contents to become independent and conscious processing must start responding to it. And only after all responses have been tried will it relegate the stimulus to the permanent (try no more responses) state. In this state subconscious STMs will not highlight / make interesting these stimuli and just include them in their sequences. However if a permanent stimulus follows or is followed by another familiar stimulus but forms an unexpected sequence this will be highlighted.
But maybe this subconscious sequence recognition should be across and between all senses. Surely it should recognize a combination of a sound pattern and a visual pattern that occurs simultaneously in a sequence. Ideally it would combine the largest changed combinations from each sense and form a total changed stimulus. Then sequences would be formed from these. With more experience and smaller combinations of things changing smaller sequences would be recognized independently. When the smallest sequences are violated with unexpected stimuli and the trigger stimulus becomes independent then responses can start to be made at this granular level. The lower granularity sequences will also be recognized as familiar and be removed from the largest changed combinations. Thus the process would find the biggest changed combinations from each sense. Then all active S-Habits would remove the familiar changes within or across senses. What is left (if anything) would attract attention.
This is similar to what currently works in Adaptron. However the S-habits are only those that have had conscious attention paid to them and are in LTM. I need to form S-Habits out of sequences that have formed for the first time in which there is no expected next stimulus. Thus these novel stimuli must be paid attention to so they get put in LTM and their first sequence gets formed. They cannot stay in STM waiting for their first next stimulus.
27th April 2010 STM and LTM
I have realized I don't need STM if I can come up with a structure for LTM that preserves the episodic / sequence information and redo-interest for habit execution plus also retains all the higher level sequences adjacent to each other for representing their sequential combinations. A stimulus or sequence starts out as unknown with no known next stimulus. It then gets a next stimulus. At this point it is part of a longer sequence. It and the sequence could be independent and the sequence cannot grow any longer or it may be dependent and waiting for the next stimulus. If it is independent then we definitely want it in LTM followed by its goal and redo-interest. But now I think the STM for accumulating long sequences before they go into LTM is a good idea. When a dependent stimulus occurs it is put in STM to start forming its longest sequence.
28th April 2010 STM and habits
I need to better understand the relationship between STM and active habit execution before I go ahead and implement it. A familiar level-1 stimulus that has only one next stimulus is placed on STM and an S-Habit is started to recognize the goal. A permanent level-1 stimulus is placed on STM and many S-Habits are started to recognize their goals. When the next level-1 stimulus is perceived the STM combines it with the stimuli in STM. All the sequences produced are placed on the S-List. Habits then reduce the interest in the sequences on the S-List. Novel sequences produced in STM when an unexpected next stimulus occurs will remain interesting on the S-List. They may have resulted from a novel stimulus. These interesting sequences will be removed from the STM. A sequence in STM that gets its expected dependent goal stimulus stays on STM and the parallel S-Habit stays active. A sequence in STM that gets its expected but independent goal stimulus is removed from STM and its parallel S-Habit completes.
In summary, the STM generates all the sequential relationships possible from the incoming stimuli based on the previous stimuli. The sequences are placed on the S-List. The active habits reduce the interest in the known sequences. The unexpected sequences attract attention. Maybe STM gets cleared when all its sequences are placed on the S-List and gets restocked again with the trigger stimuli of all the active habits and the attended to stimulus which may be a novel one. Permanent stimuli are placed on STM when their backgrounder habits are started.
1st May 2010 Creating Sequences
The logic behind creating sequences of stimuli includes the following. If you have attended to an S-level-1 stimulus and stored it in LTM then if it is dependent or permanent put it in STM to form a sequence. If it is novel don't put it in STM, no known sequence to form. If you have attended to an S-Level>1 stimulus and stored it then if it is permanent or dependent store its goal part in LTM because we want to form a sequence if possible using this goal part. It should therefore be in the STM. If it is novel or independent but not permanent then don't store its goal part in LTM because we want to see what comes next, not form a sequence. When structured this logic is:
Attended to stimulus is stored in LTM
If stimulus is dependent or permanent then
If at S-Level=1 then
Put it in STM
Set up any S-Habits
Else at S-Level>1 then
Put its goal part in STM and in LTM
Set up any S-Habits based on goal part
Else if stimulus is novel or not permanent independent
If S-Level at any level then
Perform any action for familiar stimulus
However the situation arises where the attended to stimulus is dependent (not permanent) but is comprised of permanent parts. Here the Else S-Level>1 part should only put its goal part in STM and start S-Habits based on the goal part if the attended to stimulus is also permanent. Thus the Else part should only work if the attended to stimulus and its parts are in the same permanent or not state.
2nd May 2010 Becoming independent
Since I have reengineered STM processing I have been using the strategy that any familiar stimulus that follows a novel stimulus will terminate the sequence containing the novel stimulus at its end. This allows the 1st time sequence ABC to be terminated when the next stimulus is an A, B or C. However if M is familiar it will end up terminating the AB in ABM and the DE in DEM if A, B, D and E are all novel. This should not happen because AB has only one next stimulus and DE has only one next stimulus. The two sequences ending with M should not be split before the M. The idea is that as long as a trigger stimulus has only one goal stimulus then it forms a sequence of dependent stimuli. Thus I must go back to my previous strategy which is as long as one S-Level=1 stimulus is familiar and in the sequence i.e. it repeats, then it becomes an independent sequence.
Another thing is happening as a result of my current design, which includes a LTM that is used to execute S-Habits. The longer the sequence the more times it has to be repeated before it reaches its longest point. Each repeat produces the next higher S-Level of binons. This is not natural. I have the rule that a novel sequence of two stimuli can only be comprised of two familiar stimuli, which must have been experience previously and placed in LTM.
I have decided to represent LTM as mentioned on the 8th March 2009.
16th May 2010 Design notes
The dependent stimulus trigger should be related to other dependent stimulus goals with an actn of listen$ and always have a Rslt pointer to the sequence they form. The S-Level of the trigger and goal must be the same and their parts should share a subpart. As soon as the trigger stimulus becomes independent all the future links must take on a structure of a goal stimulus with an actn but no Rslt pointer. Then when the trigger stimulus becomes permanent and dependent again all the links must have no actn and a Rslt pointer. What happens to the links when the transition to independent happens and when the transition to permanent (dependent) occurs? I don't want to wipe out the dependent link from the 1st state by placing an actn value in it if it gets the goal stimulus. And I don't want to remove actns from independent action links once it's permanent. I really need two chains of associations, one for sequences of stimuli and the other for actions and goals.
21st May 2010 Sequential gaps
I believe I need to introduce sequential gaps in sequence recognition just as I have in spatial recognition. This is used when we select sounds from the environment from just one source that is not continuous and there are many such sound sources.
14th June 2010 Where information
I have been struggling with the correct data representation for the where information that goes with the "what" information for a stimulus. When sensors are independent there are no reflections or negatives just patterns of values (symbolic or reading changes). There are also no contrast or width patterns. These patterns are spread over a combination of sensors identified with a pattern of sensors on a particular sense. To find an expected stimulus attention must be paid "where" the stimulus is expected. In the case of independent sensors this is done using the same sense and sensor pattern. But for stimuli that are multi-modal (across several senses - P-Habits) the "where" information must also contain a pattern of senses. I need to combine the sense with the sensor patterns into sense/sensor objects for each sense. At the same time for this sense and sensors I would combine the Value, Width and Contrast to form the VWC object. Then sense/sensor objects need to be combined to form a unique multi-modal 'where' object. The VWCs would be combined in unison. The multi-modal 'where' object combination must then be attached to the final value, width and contrast 'what' object to give a unique experience.
However when dealing with dependent sensors everything about the 'where' of an object is relative. And to find an expected stimulus attention must be paid 'where' the stimulus is expected. There are no sensor patterns to use. However sense and multi-modal sense 'where' information is still required. Instead of sensor 'where' patterns width patterns of values and gaps including reflections are necessary. If readings are graduated then contrast patterns between readings with reflections and negatives are used. If readings are discrete then patterns of symbols and gaps with reflections are used. So, paying attention to an expected stimulus involves searching the sensor array for a pattern with the same or 'similar' structure, orientation and contrast. 'Similar' could be the expected object with a different orientation or contrast or something with the expected contrast and orientation but a different object etc. Whatever the difference is will attract attention and that is how reflection information can become a stimulus such as when faced with a T-junction in a maze. Both left and right routes look like the same object but reflections of each other. Thus reflection and negative information must be combined with the 'what' object to give a unique experience.
16th June 2010 Entire Tree
On 23rd Aug. 2009 I concluded I needed to create the entire tree of experienced stimuli whether or not the higher level combination objects were interesting due to sensor level changes. This was because an active S-Habit might be expecting one and it would therefore be created waiting for FindInstead and because once I attach interest levels to binons because / when they have emotional value I will want this to attract attention.
17th June 2010 STM per Sense / sensor
I am at a point where I feel I need to have a STM for each sense and for each sensor if they are independent as mentioned on 26th April 2010. This is because of the following scenario. Consider 2 senses with 'A' occurring on sense #1 and 'X' or 'Y' occurring on sense #2. If the sequence occurs where A&X is followed by A&Y I want the change from X to Y on sense #2 to attract attention. If I have just one STM then the sequence of P-Habits is formed A&X, A&Y and the Y does not attract attention. If I have a STM per sense then the sense #1 - STM#1 detects a repeated 'A' that will be of no interest. Sense #2 - STM#2 will form the X, Y sequence which will remain interesting.
I'm considering starting things off with the zero objects in each STM and the P-Habit combination 0&0 of these as the primed binon experienced. This P-Habit should also be in its own STM (STM#P). It will be the largest stimulus so far, dependent and interesting. Next the 'A' and 'X' will occur. Then the STM#1 will contain 0 A and 0,A. STM#2 will contain 0 X and 0,X. Since both of these will be new their combination will be new. The 0,A and 0,X sequences will also be dependent. The A&X P-Habit will be formed and placed in STM#P. However these two sequences could be combined to form a P-Habit of sequences 0,A & 0,X that would be the largest stimulus so far. So what will be in the 3rd position in the STM#P. The illustration below shows the two possibilities. It is either a sequence of P-Habits or a P-Habit of sequences?
STM #1 0 A 0,A
STM #2 0 X 0,X
STM #P 0&0 A&X 0&0, A&X or 0,A & 0,X
I'm inclined to think it should be a P-Habit of sequences. This keeps each sense's sequence together as a unit. It would also allow the length of one sequence in the P-Habit to be longer than another sequence.
The 2nd A on sense #1 will cause A to become independent, the STM to be empty and A will be uninteresting. The Y on sense #2 will create the STM sequence 0 X 0,X Y X,Y 0,X,Y which will all be dependent and interesting and thus the stimulus that attention will be paid to.
30th June 2010
See the 2010 Scientific Research and Experimental Development (SR&ED) tax credit claim.
Details about the Canadian Revenue Agency’s SR&ED tax incentive program are here.
2nd July 2010 More Generalization / Specialization
A more detailed analysis of the subject discussed in early September 2009. If a stimulus consists of two parts S1 and S2 either in parallel or sequentially then these parts are on the STM list of stimuli. If there is no exact match interest (from the sensor detection of change) or exact match expectation of interest (from memory with a redo interest) but one of the parts has an interest or expectation of interest then the part will have been the attended to stimulus. In this way the largest interesting combination attracts attention and becomes the trigger for the next action selection. However it is possible for this largest combination (specialized) that attracts attention to have no interesting next action to perform. But before a reflexive action is done partial matches (similarity) of the attended to stimulus are investigated. The possibilities include:
- S1 and S2 are sequential and the second half of a sequence S3 + S1 + S2.
- S1 and S2 are sequential and S2 is the second half of a sequence S3 + S2.
- S1 and S2 are sequential and S2 has been experienced by itself.
- S1 and S2 are parallel and the other part of a combination of S1 & S2 & S3.
- S1 and S2 are parallel and one or the other has been experienced by itself.
And these possibilities have action sequences that are worth retrying (a redo interest).
In 4/ and 5/ the attended to object is part of possibly many things or made up of two parts. What it is part of requires going up the binon tree to all the special combinations that contain it and this is not simple with the current data structure. This would mean we are looking for a more specialized situation in which the attended to object occurred. The two parts it consists of are easy to find. This would be looking for a more general feature or property in the attended to object that might apply in the current situation. This is also what we do when just part of the scene changes. We learn to react to the part that is more general.
If we are in a situation where S1 and S2 have occurred in parallel and S1 has one response to do and S2 has a different one do we do them both in parallel?
In 1/ and 2/ the attended to sequence or the second part of it is the last in possibly many sequences. These are all more specialized sequences. These are not simple to find with the given data structure. In situation 3/ the S2 triggered action and redo interest are easy to find. This is looking for a more general situation just based on the 2nd part (most recently occurring) of the sequence.
Generalize before specialize
I have said previously that we generalize before we specialize. In fact we see the entire scene and start exploring it first. The entire scene is very specialized because it is high up on the binon tree. If we do something and the entire scene changes then we continue to focus on the entire scene, not its parts. When only part of the scene changes we then explore this part. The parts are more general because they can reoccur in many different scenes in many different combinations. So we actually specialize before we generalize. But we can learn a very general behaviour that is two general. For example, touching anything that looks smooth. And then we need to specialize / discriminate because we find not all smooth things when touched are rewarding. Each time we find an unexpected result we would keep the more specialized trigger information. But how can this work if only the more general trigger information was conscious when the action was started that produced the unexpected result?
3rd July 2010 P-Habits
P-Habits are multi-modal stimuli. That is they are combination of stimuli from 2 or more senses. A question has been asked previously (17th June 2010) if P-habits should be formed each cycle out of the stimuli from each sense and then sequences formed from these P-Habits or should sequences on each sense be formed and then P-Habits formed as combinations of these sequences. The answer appears to be the later. Form sequences per sense and then combine these sequences to form P-Habits. But then can sequences of different lengths be combined as long as they both terminate at the same time? I would say the source sequences would have to be of the same length, start in the same cycle and end in the same cycle. But also the source sequences must both be dependent or independent. This then defines what I mean by terminate.
16th July 2010 List of To Do's
The last list of things to do was 10th March 2007. Today's list is in no particular order.
- Thinking could be expanded to look ahead 2 or more steps. Add a train of thinking which would have to have some reason for stopping if a desirable goal is not found.
- Should be combining actions in sequences once learnt.
- Learnt action sequences should be started subconsciously so that additional actions can be started on more than one device before the next input. This would create parallel action habits.
- Could complete the recognition of stimuli from graduated senses, forming patterns of lines.
- Explore in more detail the use of graduated readings from independent sensors or senses.
- Add pleasant and unpleasant stimuli to control the practice, repetition and desirability of action sequences.
- Explore generalization (categorization) / specialization (discrimination) more thoroughly.
- Explore the storage of expectations / thoughts with trigger stimuli
- Explore the storage and use of interest as a stimulus.
- Improve the World model /simulation to put symbolic values on walls, 8 sensor body, 2 wheel devices.
18th July 2010 Permanent stimuli
Now that I have enhanced the World and added Body 5 and fixed some bugs I come back to a familiar question about permanent stimuli. Adaptron gets stuck looking at the same scene that has become permanent and stops doing anything. I could have it start looking at the parts of the scene, which means it may be looking at independent stimuli that comprise the permanent one. If there were only one sense and one sensor this strategy would not work. If it were human it would perform some orienting responses and pay attention to parts of the scene. After the parts are explored boredom would set in. A baby would respond with crying. Having read the 20th Jan 2009 I believe what I need is a reactive response due to boredom when a permanent stimulus repeats. This would be similar to the fear reaction or reflexive response from pain. This idea was expressed on 15th July 2005. The reaction response would not be part of a learnt action sequence and no memory would be kept of it.
20th July 2010 Action sequences
I want to start forming RSR action sequences when 2 action habits are being performed in sequence, each to validate / confirm actions that resulted in past interesting goals. This means that when there is an action habit being executed at level 1 concentration (confirming the experience) and it gets its expected goal, if the goal starts another action habit to confirm an experience we must start to form the RSR pattern. This action sequence could then be kept as the most recent action tried for the 1st trigger independent of what final goal stimulus occurs.
23rd July 2010 Practice
The practice of action sequences is all about concentrating on the steps being done and at any point you think of (recall) a better way of doing a part of it you take this action instead. This alternate action becomes the new way of doing it. In more detail: When repeating a practiced habit it is started consciously with a desire to do it and get the expected goal but it is done subconsciously. One may pay attention to the stimuli that result. If in this paying attention a stimulus has an alternate action other than in the practiced habit and the expected goal is interesting then the alternate action will be done instead. Mentioned 7th July 2009
I have Adaptron forming action sequences when two primitive actions are performed sequentially non-reflexively. They must be performed at concentration level 1 in order to repeat a previously interesting experience. When the trigger occurs, the first action is performed. Whether the first action habit gets its expected goal or not the action sequence is begun. When the goal is obtained and the second action is performed the action sequence is created containing the feedback stimulus and second action. But it is not associated with the first trigger until the final goal occurs.
However on 11th Jan 2004 I pointed out that when practising a habit if one gets an unexpected result it produces the feeling of failure, annoyance. And if one gets the expected result it produces a feeling of success, satisfaction or accomplishment. This certainly applies to a single habit. But does it say anything about the formation of an A-Sequence when two habits are being performed sequentially. Does one need the 1st habit to succeed in getting its expected goal to start the creation of the action sequence? And does one need the second habit to succeed to complete the action sequence?
It would seem realistic that the second habit's goal must succeed in matching the expected goal for the action sequence to be kept as a useful sequence. But does the first habits goal need to be achieved to string the two actions and goal into an action sequence. If the 1st action goal is not achieved then one has a failure but also an unexpected stimulus. This means the sequence is interesting and thus not being practiced. So both habits need to be successful in accomplishing their goals in order that the A-Sequence is used.
25th July 2010 Practice versus Subconscious performance
When two action habits are being practiced in order to form a new action sequence we are concentrating on the performance of the first and second habits. Both must achieve their expected goal stimulus to form the new sequence as a single habit. The reason we start the practice sequence is that the second action habit has an interesting stimulus. The first action habit does not need to have an interesting goal. Only by thinking ahead one habit can the interest in the goal of the second habit be determined.
However when we start an action habit consciously but perform it subconsciously we are not concentrating on it and may or may not get its expected goal stimulus. But the reason that it was started is that its expected goal was interesting not a subsequent goal being interesting as in the case of practice.
What happens if we are repeating a learnt action sequence (maybe as the 1st habit in a sequence we are trying to practice) and don't get its expected goal? The action sequence should be the action on this new unexpected action habit.
26th July 2010 Generalization and Practice
On 31st March 2007 I tried to explain generalization. On further thought this is my idea. All objects are aggregations (made up of) parts. The type of an object (generalization) is determined because one of its parts has a particular value (is a particular object). Thus any part of an object at any level of decomposition can be used as a typing characteristic. It is this typing part that is used in a partial match when determining alternate actions to try because all past tried actions are not producing any results of interest. Thus in my test run of 21st of July 2010 I have a partial match of the second stimulus in a sequence and decide to try the action based on the partial match (more general situation). I was not updating the interest in re-doing the general case when using its action in the specialized case and decided to change this strategy. However now I am having 2nd thoughts. If I don't update the general habit's redo-interest it will continue to be tried whenever it partially matches the specialized situation. However, once the particular specialized situation and generalized partial action has been tried why doesn't this stop the general partial action from being used again? An exact match is always chosen before a general / partial match is chosen. This would mean the logic for choosing from possible actions must be based on the goal and its redo-interest, not just the redo-interest. The partial / general match with the same goal would not outweigh / supersede the more specialized experience.
Let us consider a concrete example. You have learnt a general habit that when you see a dog (general trigger) and you say "Here boy" (the action) it comes over to you wagging its tail (interesting result / goal). Now in a specialized situation you are at the zoo and you see a dingo (a type of dog) in a cage. The specialized trigger is comprised of zoo and dog. You have no experiences (habits) with an expected interesting result in this situation so you use the general habit triggered by the dog and say "Here boy". Your expectation is that of the general habit.
The four possibilities for what could happen result in different learning.
- The dingo could come over to you wagging its tail, which matches the expected goal of the general habit.
- The dingo does nothing.
- The dingo barks at you, which we will say is frightening.
- The dingo rolls over which is something totally new / interesting and unexpected.
In 1 the expected goal is obtained and thus the interest in redoing this in the zoo with a dingo is zero. The general habit remains unchanged. If you were presented again with the zoo and dingo even though the general habit gives you an expected interesting result you would not redo the general habit. The specialized situation can produce the same result as the general habit and this knowledge takes precedence over the general situation.
In 2 "nothing happens" is unexpected. This is the same as 4 in which an unexpected result occurs. This means this specialized habit will be tried again when presented with the same specialized situation.
In 3 a frightening result would be associated individually with the parts that comprise the specialized trigger.
27th July 2010 Generalization and dependency
On the 11th Feb 2008 and 1st Sept. 2009 I addressed the question about generalization and how it may be learnt. One important factor as mentioned on 3rd Sept 2009 is that the parts of a P-Habit remain dependent on each other until one occurs / changes without the other. This is just another way of saying that all the parts of an object change in unison else they are separate objects. I don't explicitly represent this information yet in Adaptron. But it is important for action habits because when an object is made up of interdependent parts they cannot be used in partial matches. Partial matching is only done to independent parts because only these are seen as objects. The dependent parts form the whole and there is no action habit exploration of them. The 6th April 2010 may be the solution to forming and maintaining dependent and independent P-Habit objects.
Using the 3rd April 2010 sequence, when ABCD is replaced with ABED the ABD retains its interdependence and is independent of the E. ABD cannot be subdivided further for exploration. However the E and the C may only occur with the ABD. Are the E and the C now independent? Not until they can occur with some other combination instead of the ABD. Using XZLN changing to XHLP makes XL an independent combination. But ZN is not independent. Nor is HP. This seems to imply that only the combination of values that remain the same from one frame to the next become an independent whole. But then what do we make of XZCD next. X stays the same so it becomes independent. XZ has occurred before and Z is not yet independent of X. Thus XZ remains interdependent but is an independent piece. This means that a non-divisible object can contain independent and dependent parts (XZ contains X and Z). But what happens to CD? It must become independent too. How do we combine binons and their properties to determine this? We must have to find the biggest independent combination that contains the CD and notice the other part of it is different thus CD is independent. What if we got XBCD instead? Would this work? As we formed the BC, CD and then the BCD combinations we would be checking to see if they are part of something bigger whose parts were all interdependent. This would also apply for the XZ in the ZXCD. We would find the XZ is part of the XZLN and thus it is independent of the LN.
28th July 2010 P-Habits of Sequences
However, since stimulus sequences form from S-dependent stimuli the above scenario gets more complicated.
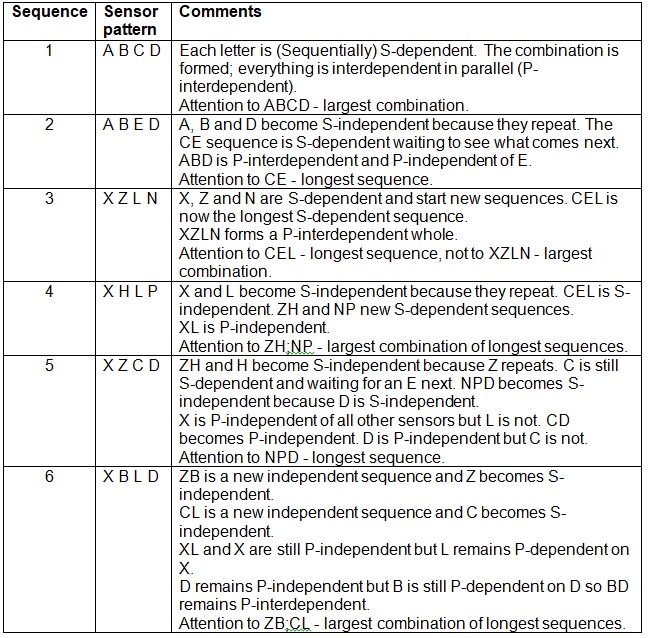
What we pay attention to at step 3 is wrong. The whole scene has changed. This attracts attention. Then the question becomes do we form the CEL sequence? Is it formed subconsciously by the sensor or do we have to be conscious of it before it is formed? If conscious is needed then does the CE get kept as an S-dependent stimulus as it was when the whole scene changing interrupted the observation of the 3rd sensor? I suspect we need to be conscious of the sequences before they are kept. In step 5 three of the stimuli have changed. This would mean that the ZH and NP sequences remain S-dependent and we pay attention to the ZCD P-Habit.
Sequences need to be learnt
My current strategy has an STM per independent sense / sensor which is collecting the sequences of stimuli and creating S-independent ones when a repeat or known independent stimulus occurs. But surely we must be conscious of a sequence before we learnt it. Only then do we have a known sequence that can be executed in parallel to reduce the change that the sequence causes. This means that each STM can perform sequence recognition upon learnt sequences but any unexpected sequence should attract attention. What does this do for the sequence I have been studying?
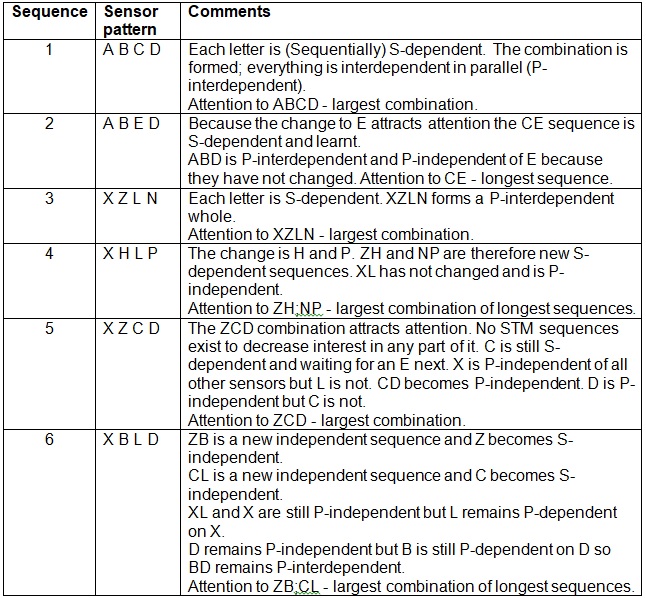
So if the combination that changes contains more than those that were being attended to then all the sequences terminate. If the combination that changes contains less than those that were paid attention to only those that change continue their sequences. For example ABCD is followed by ABCE. The E attracts attention and the DE sequence says D is dependent. This is then followed by ABFG. FG attracts attention and no sequential expectations are formed. This is followed by AHIJ. HIJ attracts attention and no sequential expectations are formed. Then KLMN is the same. But then this is followed by KOPQ. LMN followed by OPQ sequence is learnt. Then KORS occurs. PQ followed by RS sequence is learnt. Then KORT results in the ST sequence being learnt.
31st July 2010 Distractions and the Unexpected
A distraction is unexpected but not all things that are unexpected are distractions. An unexpected thing is a stimulus that does not match the expected stimulus of an active habit. If a trigger stimulus is new then it has no expectation and the next stimulus is unexpected and a new sequence formed. If the trigger stimulus is a dependent one with one expected stimulus and it gets an unexpected stimulus then it becomes dependent. If the trigger stimulus is a permanent one, flagged as expecting itself and it gets an unexpected stimulus then a new sequence is formed. If the trigger stimulus is independent, an action has been performed and it gets an unexpected stimulus then depending on its concentration level it either fails or is learnt. An unexpected stimulus that is a distraction causes your action habits to fail. If you are practising an action habit to learn it then an unexpected stimulus will not distract you unless it is part of the expected stimulus of the action habit.
S-Habits versus A-Habits
S-habits are currently assigned to each independent sensor or sense as an STM buffer. At the start of each cycle if the last stimulus in an STM buffer is an independent one then the buffer is empty with no expected stimulus. There will be an A-Habit on the habit list that will be expecting the next stimulus for this STM buffer. Dependent and permanent stimuli will remain in STM buffers. If an STM buffer holds a new stimulus, expecting nothing, whatever stimulus occurs next will be interesting unless it is the same as the before.
Distractions
I've been thinking about what to do when a stimulus is interesting enough that it is a distraction. One does not find this out until attention has been paid to those stimuli that are interesting. STM may have already formed sequences from some of these stimuli and now I have to go back and correct STM entries to just contain the distracting stimulus. I have realized that one of my very early conclusions was that an interesting stimulus not reduced by matching an expectation of an S-Habit causes the S-habit to fail. And this is what I should be doing for each STM buffer independently. The sequence of the trigger and unexpected stimulus is now known but attention will be on the unexpected stimulus. The new S-Habit decision strategy is captured in this table.
| Trigger in STM | Expecting | Next Stimulus | Interest | Trigger now | Now in STM | Sequence |
| Novel | Nothing | Same as trigger | 0 | Independ. | Empty | None |
| Novel | Nothing | Different | 1 | Depend. | Next stimulus | Formed |
| Depend. | One next | Same as trigger | 0 | Independ. | Empty | None |
| Depend. | One next | Match expected | 1 -> 0 | No change Depend. | Sequence | Matched |
| Depend. | One next | Not expected | 1 | Independ. | Next stimulus | 2nd formed |
| Perm. | Itself | Same as trigger | 0 | Perm. | Next stimulus | None |
| Perm. | Itself | Match expected | 1 -> 0 | Perm. | Sequence | Matched |
| Perm. | Itself | Not expected | 1 | Perm. | Next stimulus | Another formed |
1st Aug 2010 Novelty
I have been trying to add novelty as an interest level higher than that caused by a change in a stimulus. The idea is that a stimulus that is totally novel distracts and halts not only any ongoing action habits but also any stimuli sequences. Changes in stimuli that are not recognized by habits remain interesting and distract attention. Naturally a novel stimulus is unfamiliar and all habits will fail. But I have been forming sequences when two familiar stimuli occur in a new order. In other words if a stimulus does not get its next expected stimulus I form a new sequence but leave only the unexpected stimulus to attract attention. When the unexpected stimulus is novel not even the new sequence gets formed.
3rd Aug 2010 Unexpected processing
Normally the stimulus that is unexpected due to its interest not being reduced is attended to and the trigger stimulus that had an unsatisfied expectation becomes independent because it now has a second possible next stimulus. However in the table above for a novel trigger there is no expected stimulus. Therefore the next stimulus is unexpected but I believe the rule should be changed. The sequence formed from the novel trigger and next stimulus form a sequence which is novel. This new sequence should attract attention, not just the next stimulus. A better definition of novelty might be any stimulus, singular or sequential, that has no expected stimulus. And maybe these attract attention before those that are just unexpected (remain interest from a sensor value change). In the case of a dependent trigger stimulus followed by an unexpected stimulus and forming a 2nd sequence for the now independent trigger, the new sequence would have an expectation from its unexpected stimulus.
5th Aug 2010 Sequence formation
A little more detail is needed with respect to what remains in STM and what sequences are formed.
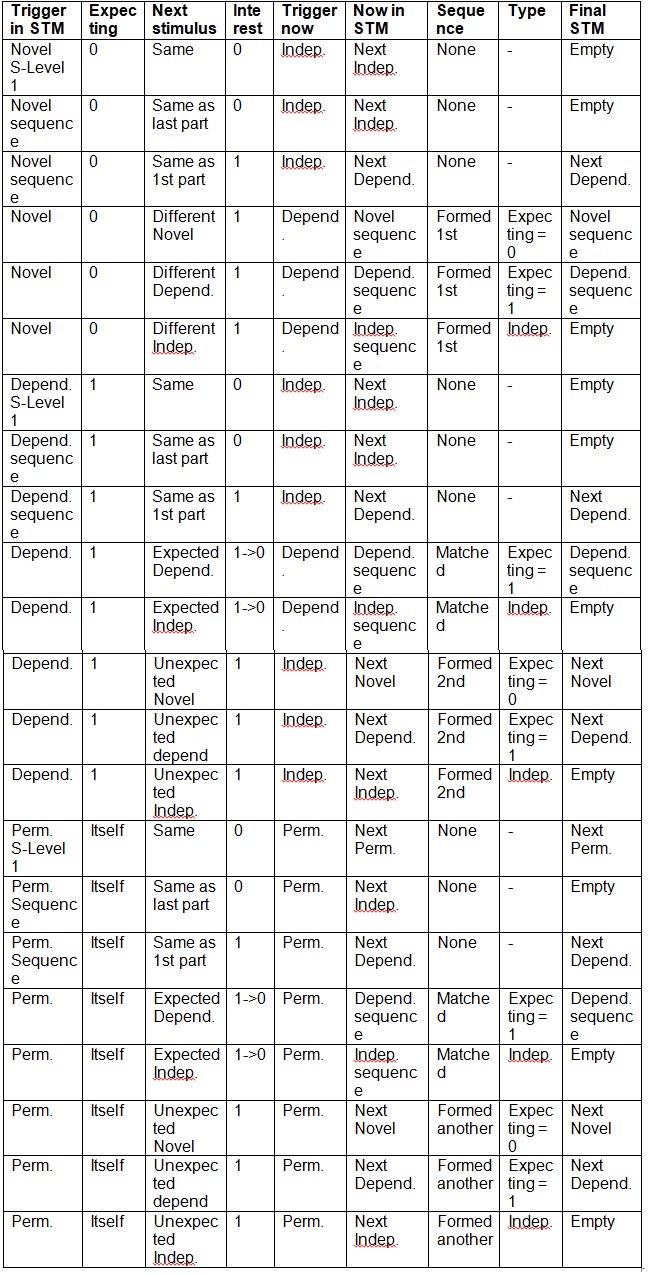
When the next stimulus is permanent it acts exactly as though it was dependent. A permanent stimulus as a trigger is marked as expecting itself but it may have no expectations at all because it has always been followed by itself up to the current point.
Distractions
When performing a reflexive response there is no expectation of a goal and no action habit is being done. If a novel stimulus occurs (one without any expectations), I have been stopping the recording of the response and goal action sequence. I think that since there is no expectation the action habit that occurs should be remembered independent of whether the goal is novel, distracting or familiar.
7th Aug 2010 Subconscious A-habits
When will subconscious action habits ever be started once they are learnt? They have been done once and this has proved that the same goal can be obtained. There is no longer any interest in the goal because it has a zero interest after satisfying the expectation of the A-Habit. If subconscious A-habits never begin then attention cannot be paid to other stimuli in the environment in parallel with action. All actions are conscious. You need subconscious A-Habit execution to be able to consciously listen to the piano music while subconsciously playing it (self-entertainment). You need it to walk along the street while talking to a friend. A subconscious A-Habit is always started with a conscious trigger but from then on it executes subconsciously. If it fails, for whatever reason, it does not interrupt consciousness. It just stops. The unexpected next stimulus is what attracts attention. Do I need to introduce emotional feelings to have a reason to start subconscious A-habits?
8th Aug 2010 Orienting Response
Our orienting responses are done subconsciously. They are triggered by a change on a sense.
This change becomes conscious very briefly, it attracts our attention. We then perform the orienting response to better focus on the change. Usually this results in perceiving a novel stimulus. We then perform recognition of it and it becomes a stimulus that no longer distracts us because we have an S-Habit recognizing it.
The solution to my subconscious A-Habit execution is to consider A-habits that have been learnt as 'stable' things worth repeating. They are started consciously whenever the trigger situation occurs. The objective is to neutralise the expected goal. They only get extinguished when a boring (uninteresting) no change result occurs. In a way this allows one to create one’s own dynamic environment, self-entertainment. Create one’s own changes and observe them without having to concentrate on the actions. This becomes a more dynamic way to explore ones surroundings. If at any time while the subconscious A-Habit is being done one realises there is a different action that can be done to obtain a more interesting result one can do it. This then overrides what the subconscious A-habit is doing and it may stop if it fails to get its expected feedback stimulus. However if this different action does not interfere with the subconscious one we are doing two actions in parallel.
One of the potential problems will be that given a certain situation it will continue performing the same action. However generalization and thinking ahead may result in different actions being tried. These techniques may also shorten a long chain of actions that are inefficient.
These ideas mean I have to change my understanding of boredom. It is no longer when a habit gets its expected stimulus and reduces its interest to neutral. Boredom is when no change at all occurs and you have nothing of interest to reduce by an active habit. And when boredom of this nature occurs reflexive responses are performed.
9th Aug 2010 Generalization and Practice
On the 26th of July 2010 I said that situation 2 where the dingo does nothing was the same as 4 in which it rolls over. This is wrong. In situation 2 no change occurs therefore boredom occurs and the next reflexive action response or alternate partial match response should be tried.
10th Aug 2010 Boredom
I had a problem yesterday with recognizing when a permanent stimulus repeats i.e. is boring, in order to perform a random response. I also need to recognize boredom on any sense / sensor so that I can detect when a learnt A-Habit needs to try the next reflexive response. I have realized that I need to recognize this per STM. I need to retain the previous stimulus for each STM before it is flushed. This includes independent stimuli. It also includes the long sequences, not just S-level 1 stimuli.
13th Aug 2010 Redo Interest
I am not sure what strategy to use to determine redo interest when a previous action (1) has resulted in an interesting goal but a more recent action (2) is neutral. I'm not even sure this can occur because when the previous action (1) was the most recent and would be chosen for repeating its redo interest is neutralized. But I do have a situation where 1 has a boring interest and 2 is neutral. Should the boring interest overpower the neutral interest in 2? Or should the strategy be to always use the most recent action habit?
Storing thoughts
Would it also make sense to combine the expected goal with the trigger as a single stimulus? The purpose would be that given a desired result one could select an appropriate action to perform. This has been asked before.
Sequences of Independent stimuli
The next question is; should sequences of independent stimuli be formed once the trigger is used to start a subconscious A-habit? In today's test run #1 a repetition of independent stimuli is not noticed. At this point one is concentrating on the stimuli only. Isn't thinking a sequence of independent stimuli? Maybe with thinking turned on the repetition would be detected. But even without thinking the loop should become conscious. Would a STM for just the conscious independent stimuli do the trick? Would permanent stimuli be put on this STM? Probably not. They are ones for which any next stimulus can occur.
16th Aug 2010 Conscious STM
I've been trying to fully understand the role and functioning of conscious STM. The unconscious STMs per sense or independent sensors are there to recognize the longest possible sequence of non-repeating instantaneous stimuli. These sequences are then combined to form P-Habit stimuli. These are then called independent stimuli. They have an interest level of interesting if they are different from the previous independent stimulus or are boring if they are the same. They have more than one expected next stimulus so responses are being tried to explore all possible next stimuli.
Conscious STM keeps a list of the independent stimuli to which attention has been paid. One of its important functions is to build up sequences of independent stimuli as in "chunking". A second important function is to recognize a repeated sequence of these independent stimuli. Any two stimuli in such a sequence could be at different S and P levels. I believe it has to build up these sequences even when it is performing a reflexive response, a reaction or practising. Then when the stimulus becomes permanent it has a list of all possible next stimuli even though some may need a response to invoke them.
However this begs the question, when does a sequence get flushed from conscious STM? One cannot go on forever building bigger sequences of independent stimuli. For unconscious STMs it is whenever a repeat stimulus occurs or an independent stimulus occurs. The repeat could work for conscious STM but there must be other criteria. Thinking may interrupt it. There does not feel like any memory for one’s train of thoughts. There would not be the concept of next expected independent stimulus because many are possible. But one could use the concept of unexpected. This could produce interest. Starting to practice an A-Habit should also flush STM. We also have the idea that only emotionally important experiences (learnt ones) from STM go into LTM. However Adaptron is placing learnt experiences into LTM immediately. They don't have to pass through STM first.
If A-habits are being practiced then there is definitely a single next expected independent stimulus. But when an A-habit is started consciously but runs subconsciously there is no such expectation. One is left to think, pay attention to what is coming from the A-habit execution or pay attention to some other stimuli. The subconscious A-habits are reducing the interest level of their expected stimuli to neutral as they occur. If one is attending to this sequence of neutral independent stimuli then the conscious STM can detect a repeat. But we also have A-habits such as peddling a bike where the repetition is intentional. Obviously the changes on another sense or sensor are those that make the repetition worthwhile and worth continuing. When one tries to pay attention to just the repeating feedback stimuli one's mind wanders very quickly to thinking or other senses or sensors. One is always searching out change of some form or other. So it is reasonable that if one does not have another sense or sensor and thinking is turned off then one starts trying another reflexive response when a repeat occurs.
Then the question is; is a sequence of independent stimuli another independent stimulus that needs to be explored? Or is it a dependent stimulus? Does one have to explore the first stimulus of a sequential pair until it is permanent and only then combine it with the second to form an independent stimulus? I suspect a sequence of independent stimuli is a dependent stimulus. That is until there is more than one next independent stimulus. But there must be more than one since the second is independent.
One also seems to be able to retrieve a particular stimulus from STM based on some feature of it. What one does is associate the stimulus with some idea and then retrieve it based on this idea. For example when multiplying 42 by 57 one 'labels' the 7x42=294 with the idea of 'the 1st result' and then can retrieve it based on 'the 1st result' cue. I suspect this idea is actually a grounded concept formed from separation / width / contrast patterns from a particular sense. It may be the visual concept of 'the top one'. This may have come from the actual experiences of doing long multiplication on paper.
Parallel subconscious A-habits
Multiple A-Habits can be done in parallel when there are many independent sensors. Each muscle is independent and detects its own feedback stimuli. In one cycle multiple reflexive responses can be done provided the boring stimulus from each sensor is treated independently.
Cascade of changes
An action response would normally be a request to a device to perform a certain change. A big change may not take place in one cycle and thus result in a cascade / sequence of stimuli without any intermediate responses.
17th Aug 2010 Expectations & STM
Sequential pattern formation must continue to take place independent of whether actions are being done or not. This is because we always have expectations of what possible next stimuli can occur. The longer the past sequence is matched the fewer become the next possible stimuli. This is the only way we can get surprised when something unusual (unexpected) occurs. So sequences of independent stimuli are created as a result of actions. Repeated stimuli will end such sequences. I'm not sure what else will end them.
The list of A-Habits being done provides a list of all the expected next independent stimuli and this will reduce the interest in these stimuli when they occur. When A-habits fail they don't notify consciousness. It is the unreduced interest in the unexpected stimulus that is detected by the attention process. Therefore, do I need a conscious STM to recognize sequences of independent stimuli and the unexpected ones? If A-habit execution is to replace the idea of a conscious STM then it also must detect repetition. I think I need BOTH mechanisms. I need A-habits that can run subconsciously. They will reduce stimuli interest but also perform the responses provided the right feedback occurs. I need a conscious STM to recognize repetitions and add to sequential expectations of independent stimuli. I don't want A-Habits to recognize repetitions because that may be the objective of performing the A-habit in the first place. I want to be able to redo a repetitive action sequence when the objective is to experience a change on another sense or sensor. Thus A-habits should not be marked as boring. The conscious processing of independent stimuli should be the determining factor for doing, practising, redoing or not doing an A-habit.
I have A-habits that run subconsciously. I have sequences of independent stimuli being created in LTM as NxtLnks. They don't form higher level combinations of independent stimuli because they are always separated by responses. They do have a redo interest that could be 'boring'. Their redo interest is revised when they are being practiced which does involve A-Habit processing. So I don't believe I need a separate conscious STM. I need conscious A-Habits being practiced to recognize repetitions but not when being done sub-consciously. But when doing the sub-conscious A-Habits what happens if I am conscious of the stimuli sequence they generate??
The 'get up from sitting' A-Habit part of the 'go to the bedroom' A-habit is the same as the 'get up from sitting' A-habit part of the 'go to the kitchen' A-habit. They differ in their second part. However when one starts the 'go to the kitchen' A-habit subconsciously one had a specific reason / goal in mind. For example one was hungry and the goal was to make a sandwich and the first sub-goal was to get to the kitchen by doing 'go to the kitchen'. The whole action sequence is done automatically and sub-consciously. It is the one started and not the 'go to the bedroom' one. When arriving in the kitchen the stimuli from this situation then probably cues the next action sequence to make a sandwich. While the 'go to the kitchen' responses are being done the conscious STM should be following the incoming stimuli created. If so it is continuing to expect the next independent stimulus of the specific A-habit being done.
One thing I have to be able to do, when executing the same A-Habit again at neutral concentration, is to remember the unexpected stimulus and practice a new A-Habit to respond to it.
Sequences of Permanent stimuli
Now I am faced with the challenge of defining the rules for sequences of permanent stimuli. The stimuli in a sequence of dependent stimuli are always happening on the same sense or independent sensor. Sequences of permanent stimuli contain stimuli from all sources since they are formed consciously when no more responses are performed for an independent stimulus. It is reasonable that a sequence of two permanent stimuli becomes independent so the sequence can be explored. This already happens for stimuli from the same source. But what about a sequence of two permanent stimuli each of which is a sequence? See test run-1 from today.
18th Aug 2010 Memory
The purpose of memory is to hold past experiences. This enables one to identify situations that are familiar or novel. It therefore enables one to detect repetition. It also allows one to predict what is expected to happen next or what is expected to happen at the same time. The process of thinking uses this predictive ability to help in decision making. Thus a conscious STM should hold conscious experiences for a short time. This would seem to include thoughts. In this respect it is a means to determine if thoughts repeat. It also allows one to obtain past thoughts before they are lost as in when mentally multiplying large numbers. If sensory experiences go directly to a long-term memory they have no need to be in a short-term memory. The long-term memory should satisfy all the functional needs.
My previous dependent and independent stimuli are primitive forms of conscious short-term memory. They allow me to detect repetition and are used to create the longer-term memories when the next stimulus occurs. But I also keep track of the longest previous stimuli that were most recently flushed from the STMs. This allows for detection of a repeat of the longest stimulus and setting of the interest level to boring on that source. But this all adds complexity. A simpler approach would be to have a long-term memory that keeps track of all possible sequences and parallel patterns of stimuli and thoughts independent of whether they result from an action or not. One would not need to remember thoughts over the long-term because one can recreate them by recollection of sensorial experiences. Although, because new experiences are added to memory, it may not be possible to reproduce exact thought sequences. But that is an advantage because one is always using the most recent experiences on which to base ones thoughts.
However memory does not need to keep repeats of experiences. It records the first occurrence because it is novel. The occurrence may be a single stimulus or a sequence. This is then used to recognize repeats. If repeats are conscious they become boring. If they are sub-conscious they are actively waiting for their next in sequence. Thus unexpected sequences can be detected, recorded in memory and brought to consciousness for attention should they be interesting enough.
The correct structure of sequential memory should contain the previous sequence as well as the currently being accumulated sequence. For example in the series ABCBC the memory should contain the following active sequences.
A
A B A^B
A B A^B C B^C A^B^C
B B^C B it keeps the parts that start with a B as previous stimuli
B B^C B B^C it would then set interest to boring and empty the previous stimuli
If I have LTM do all interest reduction due to expected stimuli being found I could just have A-habit and sequences execute responses provided the correct feedback occurs. LTM would also do recognition of repeats, boring etc. This would mean that LTM would keep track of sequences of independent stimuli. This would be navigated for thinking purposes.
We experience a changing and repetitive environment before we start to perform responses to explore it. Thus we build up many sequences of dependent stimuli and independent stimuli before we start to explore the independent ones. And independent ones occur many times in all sorts of sequences before we start to react to them. We start to react to them when they become boring. This means they must repeat. So the first reflexive response to an independent stimulus should not be done when it is found or on its second occurrence. It should only be done if it is a repeat of the stimulus or it has an expectation of it being boring due to a previous repeat. Then the next question is, should independent and dependent stimuli be joined in sequence. They will have been when they were both dependent. But as soon as the first becomes independent it would seem reasonable to only associate it in future with other independent stimuli. If the second becomes independent then the first would still be associated with it.
19th Aug 2010 STM previous
I realized that in the case of the ABCBC above I only need to keep the previous B^C to detect a repeat. Currently I keep A^B^C as the previous.
21st Aug 2010 Sequences of Stimuli
Having implemented a semi-functional version of conscious STM I have realized that my concepts of sequences, dependence, and repetition are not quite correct. It is true that all parts of an object or sequence change together and all the parts stay the same together. That is, the relationship between the parts is constant. However, the use of the independence concept when one stimulus has more than one expected next stimulus does not quite work for starting to perform responses. Take the sequence ABCACA for example. The C becomes independent as soon as the A repeats but this is not a good enough reason to start responses as soon as the C repeats. What I must do is form all the sequences that do not contain repeat S-Level=1 stimuli. Thus I would form AB, then BC and ABC, then CA and BCA, then AC and then the CA would repeat. I would then only react when this CA repeats. Thus I would create as many of the longest sequences possible which do not contain a repeated S-Level=1 stimuli. Then only start responding when any of these repeats sequentially. Thus ABCACBCDCECFCGCH causes no responses even though C is independent. If it is followed by FCGCH then this is a repeat and a response is done. However this fails my theory because FCGCH contains a repeated C. Maybe the repeat of an S-Level=1 stimulus is the start point for detecting a longed repeated sequence. And soon as the repeated sequence is detected then we have a stimulus worth responding to. If the full sequence does not repeat such as following it with FCGCA then no response occurs.
7th Sept 2010 2 Dimensional Sensor Array
I realized this morning that a 2 dimensional sensor array can be mapped onto a one-dimensional array and all the recognition algorithms will work for 2D provided they are working properly. They will recognize objects that move, rotate etc. This is because the gap between readings from one line of the 2D scan and the next line will be part of the object. Will it also work if the object expands or contracts? I think so because the object patterns will be level independent.
30th Sept 2010 Repeats in Conscious STM
A repeat in unconscious sensor STM may be a sequence of stimuli. In conscious STM a repeated sequence of independent stimuli may occur when one is paying attention to the stimuli from the execution of an A-Habit being done subconsciously. Does one wait for the entire sequence to repeat or does one say "I've been here before" when just the 1st independent stimulus in the sequence is found to repeat in conscious STM?
1st Oct 2010 Remembering Thoughts
Since I have heard people say "I remember thinking..." I suspect that thoughts are remembered provided they have a strong enough emotional feeling attached. One can and needs to also remember thoughts in conscious STM long enough to compare with actual sensory input. I'm sure imagery thoughts are put in conscious STM.
3rd Oct 2010 Conscious STM
Some key facts / ideas from Bernard Baars' book "A Cognitive Theory of Consciousness".
- Surprise flushes STM
- We are always looking for stimuli that mismatch / contradict predictions / expectations.
- Thinking can cause us to miss the opportunity to consciously direct an action habit (a choice point).
- Thinking includes imagery and inner speech.
- Rehearsal is needed to form chunked higher level identities
- Chunking only combines stimuli from the same sense. Is it possible that we only chunk thoughts?
- Items in STM are addressable just like LTM based on "Where".
- The "Where" of an object is determined based on relationships.
- When not concentrating / not practising we want novel / mismatches to experience.
- When concentrating / practising we need a match to experience.
- Goals / intentions and expectations / thoughts are the types of objects we process and store in STM, as though they are their own sense / source of stimuli. Is self-consciousness an awareness of STM?
- Action is done as output / subconscious, but linked to goal stimuli.
- Imagery and inner speech are thoughts, so can one have the same for the novelty feeling? - Is it a stimulus and can one have a thought about it? Based on the fact that one can name it and talk about it, it must be an object and thus a stimulus. However it is processed differently.
- Associations between sense stimuli are formed and are navigated, one stimulus invokes the other.
- This also applies for associations between the thoughts of these senses.
- "New skills are acquired only when existing skills do not 'work?' and we tend to adapt existing skills to new tasks."
- STM establishes sequential relationships between stimuli.
Is it possible that the chunks of sensory stimuli are always formed in their own sensory STM and conscious STM only forms chunks of thoughts? But the thoughts need to be of the same sense? The reading of a sequence of letters or words or numbers creates a sequential object that corresponds to the visual instantaneous parallel object that contains the sequence. These two must be associated somehow so that one invokes the other. Similarly the image of a tree invokes the word and vice versa. How is this association represented? All that I currently have for this purpose are P-Habits and Sequences in conscious STM. P-Habits form hierarchies. Is this appropriate? When you get one input to a P-Habit without the other part does this create an expectation (thought) of the other part? Sequences have “time direction”, so if the tree image is associated with the word tree how does it get represented in the opposite order? Do I need two sequences?
Is Conscious STM the place where thoughts from different senses are associated? Do these associations take the form of a sequence? This is most likely because we talk about our "train of thought". Is Conscious STM where spoken sentences are recognized and their associated idea created or is the sentence formed in hearing STM and its identity retrieved from LTM? Then does the sentence's identity as recalled become a thought? Since thoughts are goals and expectations they are the result part of my A-habits which are NxtLnks. I have previously (many years ago) decided that thinking always follows these trigger - goal sequences. Thus thinking is goal oriented / driven. It does not get the associated part of a two-part S or P-Habit binon unless there is an action that has been learnt that gets it. Then given an expectation of a goal (a thought) it finds in LTM the actual equivalent stimulus object, treats it as a trigger object and looks up its associated goal object based on the action. The recollection of this associated goal is then the next expectation of a goal (the next thought). If the actions are pay attention actions / instruction then we end up with navigation A-habits for S and P-Habits.
But what are pay attention actions? They are mental orienting responses.
4th Oct 2010 Chunking - Imagination
Chunking applies to the creation of a tree structure of thoughts. It creates a higher level thought that is the combination of the parts. The chunks created and the parts are definitely thoughts because they can be something that has no experienced equivalent. You can be told a series of three digits or random letters and create the image that represents them in your "mind's eye" without ever having physically seen it as a whole. This is the power and the process of imagination.
This process relies upon the spoken word invoking the spoken thought that recalls the image. The spoken word to spoken thought association is the pattern recognition of the spoken word in which the spoken thought is the word identifier. The word identifier acting as a trigger causes the pay attention action habit that retrieves the 2nd half of the P-Habit formed from the spoken word and visual tree.
So it is time to identify some of these mental orienting responses. There should be the ones that get the other part of a P-Habit binon. If they are to retrieve the part from a specific sense there could be many variations on this, one per sense. There should be the ones that get the second part of an S-Habit binon when given the 1st part, which may be sense-specific. [24th Oct. There is no such action as this because a dependent sequence (S-habit) is recognized subconsciously. And sequences of independent stimuli form orienting action habits]. These could all be summarised as obtain the goal object based on the given goal "Where" for the given trigger object.
5th Oct 2010 Mental Actions
I already have an action that is "listen to external senses" that implicitly includes the action pay attention to what ever attracts attention. I also need the same "listen to external senses" with a specify command to pay attention to a particular "Where". This "pay attention" action piece should make up every action. It is the "Where" part of the goal stimulus. When the goal stimulus is a thought rather than an external sense stimulus then the actions become mental actions. Effectively we are paying attention to LTM recall as though it were another source of sensory information. And in a way it is because it is our history of reality to this point in time. This means that each A-habit consists of a trigger stimulus, an action, a goal stimulus and redo-interest. The trigger is a recording of a stimulus from an external sense ("Where" and "What"). The real experience of this stimulus would match the trigger, as would the thought of this stimulus. The action is a non-physical action (just perform the pay attention as determined by the goal), a primitive action on output devices or an action-sequence. The goal is a recording of a stimulus from an external sense or a recording of a recalled stimulus from memory. They both have a "Where" part. For an external sense it points to the sense, and the expected contrast and size pattern. For a recalled memory it must be whatever attention can be paid to when performing a recall.
Loop Action Habit
As these action habits get performed the stimuli must be placed in conscious STM to detect any repetition. However the idea from the 30th Sept must be considered. If the "I've been here before" repeat occurs one may still repeat the action habit subconsciously. This would happen provided some other source of stimuli is interesting as a result of the action sequence. For example we repeat the pedaling motion on a bike subconsciously as long as the scenery continues to change. However if nothing else changes the action habit is boring. This gives us the question how do we end up with a repeating / looping action habit. It must get an interesting stimulus other than the feedback from the action sense. The simplest loop would be comprised of two action habits.
- At input D it outputs action A and gets input E.
- At input E it outputs action B and gets input D.
Each would end up with a redo-interest of novel the 1st time they occur. When they are repeated in practice mode they would get their goal stimuli from the action sense plus some other interesting stimulus. Each would be reduced to neutral redo interest and the action habit D x D would be formed where x is A E B. This new action habit would have a redo-interest of interesting due to the other stimulus (not D).
6th Oct 2010 Action recognition
I have been placing independent stimuli in their own conscious STM as they are attended to. I have been using the same repeat recognition algorithm that I developed for sense STM that builds a tree of binons out of sequentially occurring dependent stimuli. However this requires the assignment of a "Where" object to the experiences. I have now realized that I should be trying to recognize the action habit, not the S-Habit recognition binon, for a repeated sequence of independent stimuli. This is true because between each independent stimulus there is an action even if it is just pay attention (listen).
7th Oct 2010 Action Habits
There are two levels of action execution after a reflexive action has been done and a novel goal achieved. They are practising and doing. When practising we are concentrating on the action goal sequence and seeking confirmation of the goal. The action habit is reduced to doing status when the goal is achieved; the feeling of success is obtained. If an unexpected goal occurs then we have a novel action habit to practice. When two action habits are done in sequence at the concentration level, action sequences are formed. If the goal ends up being the same as the trigger, i.e. a repeat occurs this is not recognized as boring.
When doing action habits the interest in the goals are reduced to neutral because they are expected. Doing is subconscious and no update to action habits is done whether the habit succeeds, fails or repeats. Doing an action habit continues as long as the sub-goals are achieved. While doing action habits, if we are conscious of the stream of goal stimuli and we get a repeated stimulus this is boring and an alternate action is done as a reflex. Our conscious STM is flushed. While doing action habits, if an unexpected stimulus occurs, then this is novel and it flushes our conscious STM being used to detect repeats. Starting to practice also flushes conscious STM. While doing action habits if we are conscious of the stream of goal stimuli then we do the lowest level actions but no need to update action habits; we need to recognize that we are doing this unconscious action habit. We need to be aware of repeats and action choice points.
If we can think, we can look forward over 2 action habits for an interesting 2nd action goal. This then starts the action habits at the concentration level (practising) even though the interest in the 1st action goal may be neutral. When we reach the end of the 1st action we will have attended to its goal because we were concentrating on the action. When we get this goal we have a choice point. A choice point is between the executions of two action habits where we are no longer concentrating. We use the current attended to stimulus to decide what to do next. For example "going to the bedroom" and "going to the kitchen" both start with "getting out of chair and exiting study". But once exiting the study goal has been achieved there is a choice point as to which way to go. No, I think this example shows the reuse of an action sequence in two higher-level action habits. A better example might be where the action can have multiple goals. For example I "go to speak with Ann" and I find her either "looking at me" because she heard me coming (an expected stimulus in the action habit), "doing something" or "asleep". The goal I had in mind was speaking with her but the action habit failed in the 2nd and third cases because it did not get an expected goal. I'm then conscious of the new situation and must think of / retrieve an appropriate action. No, I think this example does not illustrate a choice point. We can miss a choice point because we are deep in thought. This happens when we start doing a complex action habit and pay attention to thoughts or something unrelated. The example action habit is to make a bowl of cereal with milk and a spoon. We need to get a bowl, “get the cereal, get the milk, get a spoon, put cereal in bowl, put milk on cereal, put away milk and put away cereal”. Each is a learnt action habit that can be done and relegated to the subconscious. We can only do one at a time and some cannot be done unless an appropriate trigger stimulus is perceived. This is where the choice points are. They are between the performances of two action habits where a choice is possible for which habit to do as the second action habit.
Thinking creates an expectation. These thoughts should be placed in a STM that holds an expected goal until it is achieved. The same STM could create chunks of thoughts. And if too many thoughts flow through this STM an earlier thought (goal expectation) could be lost and thus one would find oneself at a choice point with no idea why you are there.
Stimulus Interest
But just because we have an action habit that can be done, (does not need practising, redo interest is neutral) does not mean we do it. It still needs to have the trigger stimulus occur and a desire to achieve the goal. Thus the goal must have become interesting or due to thinking a second / indirect goal must be interesting. How can a goal become interesting? A stimulus is interesting because it is unexpected. But when this happens doesn't the interesting stimulus become an interesting goal of an action habit? Not if the action habit was being done subconsciously. Stimuli are interesting if they change. This is happening all the time but subconscious action habits are reducing their interest. So if we have no action habit that reduces the interest in a stimulus it becomes interesting.
When doing (not practising) we should also start all the action habits for a given trigger stimulus that involve the performance of the same action but get different goal stimuli. It is true that the most recent one is the most likely but the other goals have also occurred less recently and should be expected.
When practising and doing an action habit the concentration level is the same, so what distinguishes them? Is it that when practising we are only doing the one action habit but when doing we are doing all that have the same action. When starting both doing and practising the interest level is the same, but while performing the habit practising retains the concentration level but doing does not. Doing is done at a neutral level subconsciously. Doing action habits requires that we become conscious at the choice points to start the next action habit.
Repetition at the subconscious level of dependent stimuli does not cause boredom. Therefore only interesting and neutral interest can be generated by the senses. This is the change / no change concept. One needs conscious recognition of repetition to have boredom. However repetition of the most recent sequence of dependent stimuli on a sense does cause a sequence to become independent and thus it becomes conscious.
8th Oct 2010 Redo Interest
The separation of recognition of conscious independent stimulus sequences from the execution of action habits has meant that the conscious stimuli have an interest level based on their repetition and change while the action habits have a redo interest purely based on whether the trigger-action-goal sequence is new or not. And this is how it should be. Recognition of conscious stimuli must
- identify repetition and assign boredom and
- recognize an unexpected sequence and assign interest.
- It must also think about sequences that will result in interesting goals (pursuit of novelty).
Am I using the action habits for two different purposes? One is a store of what actions to do in a given situation (trigger) to get a particular result (goal) and the other is the interest in the goal. If the interest in a goal were associated only with it as a stimulus then actions would still be done if their goal were interesting. But would we have a way of identifying practice mode separate from doing mode.
Practice mode involves having an expectation of the stimulus goal while doing mode the goal expectation is more of a thought of the goal. If we associate interest level to stimuli only, then find action habits to do that meet interesting goal stimuli and do them subconsciously the redo interest on an action habit becomes a novelty flag for the habit. This flag would indicate that the action must be done at a concentration level to get the goal if novel and that it can be done subconsciously if learnt.
Thus when a conscious independent stimulus is attended to the first thing to do is look up all its expected goals (via action habits) and find one with an interest. This is thinking a single thought ahead. If none is found interesting one could do a second level thought etc. Assuming an action habit with an interesting goal stimulus is found then this would have started either in practice mode or doing mode depending on the novelty of the habit.
Independent Stimuli
I have decided that when a repeated sequence of dependent stimuli occur, the sequence before the repeat that ends with the repeat as part of it is independent too, not the part before the 1st instance of the repeat. For example given ABCDCD the CD becomes independent as does the ABCD rather than the AB and CD parts. Similarly if CD is known ahead of time to be independent then when XVCD occurs this makes the whole string independent. XV stays dependent.
9th Oct 2010 LTM
I can recall a series of events that occurred yesterday at many different levels of detail. I walked over to Learning Tree to return my signed contract, buy some Halls, get a haircut and buy an ice cream. I can recall the one and half-hour episode in the form of a sequence of visual snapshots and recreate it in the right order. I can remember some thoughts also about where to buy ice cream and when in the scenario I thought of them. The lowest level images are all the unique ones I observed in my travels. Anywhere there is a length of time where I was thinking I have no snapshot images for what I saw. Anywhere new images occurred I remember them clearly, such as the new carpet at Learning Tree, the wall missing the posters, the new temporary receptionist at the front desk. But I don’t remember the bowl of fruit on the front counter because it was not unusual. I can only remember the novel parts of walking along the sidewalks, an unusual pedestrian, puddle or seeing a squirrel. So obviously I have stored in LTM a sequence of these events which I can navigate. It most likely is a linked list of independent stimuli that are interesting. In some places I can’t quite remember the correct order. For example, I can’t remember the order of weaving in and out of the numerous pedestrians in the market. Each trigger situation was unique and I can remember some of them and what they looked like but not the order in which they occurred. While I was concentrating on the store names on the left, searching for the gelato store, I cannot remember what weaves I performed. So I can recreate the sequence of the trip in quite some detail. It contains hundreds of images. In many weeks’ time I may not be able to do so. The importance / novelty of the events will have been ‘forgotten’ or they will have been lost due to more recent events that are too similar to allow me to retrieve the originals. The order is more likely to be lost than the unique images. And although the majority of my LTM memories are images there are a few sound memories. I remember piano music but not the notes from speakers above the NAC Peterson piano and general music while walking through the tunnel to the corner of Rideau and Sussex. I don’t remember any particular smells (yes I do, the grass being smoked by the 3 pedestrians I passed on Parent St.) but do remember sucking a Halls while getting my haircut. I don’t remember the taste since I had tasted it before. But I do remember a little of the moving or not moving it in my mouth and the clicking I made with it against my teeth and the thought that the barber could then hear it.
Actons
I have decided to call the component that is done as the response part of an action habit an Acton. This is a short form of Action-Neuron. An action habit is represented by a sequential binon in which the response (the firing of the acton) is done after the trigger stimulus and before the goal stimulus. The parts of an acton are done in sequence. An acton consists of a 1st response that may fire another acton or primitive response/action, a middle feedback stimulus/binon and a 2nd response (R-S-R).
Interest / Desirability
I need to associate an interest level or desirability stimulus with independent stimuli. Those with strong positive or negative desirability will be retained in LTM. We will think through the action habit network for goal stimuli with strong desirability.
Triggers
The action habit triggers need not and rarely do match new unique situations as we encounter them. Some subset of the general characteristics is matched to the trigger stimuli. For example to initiate the ‘weave through pedestrians’ action habit I just need to recognize one or more pedestrians in front of me and disregard the details of what they are wearing of how tall they are. Obviously in performing this action habit in the past I have tried it many times. Each time I have initiated it on a partial match of the trigger situation’s characteristics and have narrowed down the trigger situation to a general set of properties that must be present to achieve success.
10th Oct 2010 LTM & thinking
As I recall my trip to Learning Tree etc. I recall images in sequence. It is though I am navigating the unique images (since they are the ones remembered) based on the action sequences done. I am recalling one image that matches with a trigger and then I am selecting the most recent go forward action and getting the goal stimulus. At any point I can select the look behind me action and get the scene from the other direction but from my experiences at some earlier trip. So as I am performing the trip I must record the situation as a trigger, the response selected from a generic matching action habit and the next unique stimulus as a goal stimulus. Thus we build a detailed history of the experience sequence out of action habits. The chances of ever picking one of these action habits to repeat is very small because we are more likely to perform ones where the trigger is a partial match to a generic set of properties. However, when it comes to thinking, we are always matching and picking the most recent one using the closest match to the trigger.
18th Oct 2010 Reminding (Read 3rd Dec 2006)
We remind ourselves to do something in the future based on the following scenario. In the present we are cued by a current situation to which we associate the thought of a goal. But we do not or cannot accomplish the goal right now. So we think of an appropriate future situation that we believe we will encounter and associate with it the action / goal sequence we wish to perform in the future. We do this by thinking of the goal. Then when in the future we encounter the thought about situation we recall the thought of the desired goal and this causes us to perform the action.
Repeats in Conscious STM
Following on from 30th Sept 2010 when we are conscious of the stimuli that a subconscious action habit is generating these stimuli have no interest. They occur as expected. We are likely at this point to perform thinking. This may lead to an alternate action to perform or be distracted if something novel occurs. Note that the action habit may be using lower level stimuli (more general) for its execution and the goals it obtains are not the complete stimuli as perceived. However the perceived stimuli are also expected based on our memory of the sequence. This means we remember the “what happened next” sequences. What form do these take? Are they recorded as an action habit? If so their trigger and goal stimuli are the specialized stimuli of the sequence. What form does the response take? It may just be the listen and pay attention to goal sense that is recorded.
These experience sequences with just listens in them will have interesting goal stimuli the first time they are done. But the goal stimuli will become neutral when done the second time. The 3rd time the trigger situation is encountered what will cause us to repeat the previous subconscious action and not try a new response. We must already be doing an action sequence and already have a longer-term goal in mind. We may be walking the familiar way home. The goal is to get home. A good example is that of travelling to a new place. The first time you walk along the path you are doing the subconscious walk action habit but consciously taking in the sequence of novel specialized stimuli. I’ve been to Barcelona and I found it was a really interesting city. The 2nd time you walk along the path you are validating what you saw the 1st time and it is becoming familiar and of neutral interest. Any unexpected sight is remembered as interesting. You may modify your path slightly so novel experiences occur. I would go back to Barcelona to see some of the things I missed the first time. The only reason you would travel the same path a 3rd time is if you had some goal in mind other than to take the same path as before and see what you have already seen. I might be going back to Barcelona on business. The 2nd and 3rd times you repeat the sequence are equivalent as far as motivation is concerned. There is a goal that you wish to achieve. In the 2nd case it is re-experiencing the interesting goals. In the 3rd case it is experiencing some other goal. If a reward were experienced every time you accomplishing the goal you would repeat the experience every time you could.
Thoughts are remembered
If thoughts (imagery etc.) are stored then they must also be recallable. I certainly know if I have rethought a previous thought. And given that thoughts are chunked into tree structures I suspect we have thought binons on a per sense basis. Imagery thoughts though are associated with inner speech thoughts via listen Actons as described on 3rd and 4th Oct.
20th Oct 2010 Listen = Orient
I thought a good name for the do nothing action / pay attention actions – just listen to the next input would be orient actions. The think of next stimulus is also the orient action where the sense to pay attention to is the recollection from memory. Since we chunk these recollections I also feel that whatever we can do in subconscious STM to form trees of dependent stimuli we can also do to thoughts. How do we take an image and rotate it in thoughts? I can think of a ball on a box and then rotate it until it is a box on a ball having never seen these two for real.
24th Oct 2010 A-Habit
Action habits that are learnt that can be started subconsciously are based on triggers that are object types. They are generic. They are not based on special instances of experiences. As they execute they search for the types of feedback objects not particular instances of them. Thus the "sit down" habit can function on many varieties of chairs and execute without interruption.
If we have graduated readings from an array of graduated sensors this object type that is generic is the combination of the sense, the contrast pattern and the width pattern. It is independent of the size, position, rotation, brightness, reflection, negative and level of complexity. And if one adds time / sequence the generic object type includes patterns of change in the contrast and width patterns. Are these independent of the rate of change? Specialized experiences combine the object type with the independent dimensions. However, all the independent dimensions are measured relative to other objects or a frame of reference. And I have previously decided we do not remember the absolutes. So when we remember a particular scene in detail we remember all the parts relative to each other. This would seem to suggest that these action habits have been learnt to be attached to the lowest common denominator of trigger object properties without failing. So we initially try a response in a detailed scene and then try it in any scene that has a common part. If the goal has overlapping parts with the 1st attempt's goal then these would become the new generic goal for the generic trigger consisting of the common parts. Read 26th July this year.
If we have symbolic readings from discrete independent sensors is the object type all the same for a given sense and sensor? Or is each reading a different object type? I think each symbolic reading has to be treated as a different object type and thus the only opportunity to generalize is with the parts of P-Habits.
When searching for a tree (type of object) in a scene we give the attention the generic object / stimulus and it picks out a specific one. The same must happen subconsciously for the generic objects in a learnt habit when it is being done. If we are practising an action habit the generic goal must be used by attention to find the specific goal instance. The "Where" provided by the action habits goal is really the generic object type.
Attention attracted is reflexive
Just as we try reflexive actions to establish a repertoire of action habits that contain response our automatic attention attraction process provides a repertoire of orient responses.
Looping Action Habits
This concept of A-habits being based on generic object types also helps validate the fact that a looping action habit will continue provided the specific stimuli perceived continue to be interesting. The specific stimuli perceived could contain the generic object types.
25th Oct 2010 Orienting Responses
I'm having second thoughts about whether we remember absolutes like position and brightness. I have decided that we do remember these relative to our frame of reference that our senses provide. I have concluded this because we can mentally orient our attention to "where" an object is that includes position on the retina, brightness, size and level of complexity. This means our experiences must include these properties as well as sense, negative, reflection, orientation (rotation), contrast and width patterns. We must aggregate these properties to produce an experience. Whenever a change occurs that produces a reflexive orienting attention response then the aggregation of the properties that changed becomes a possible orienting response in an action habit. This will be repeated if there is a stimulus that matches the trigger and the goal is of interest. These aggregations must be any combination of the properties. This means that a P-Habit structure must be used on them. And when we orient our attention to LTM we can select any of the same property combinations for a memory.
Interest as a stimulus
I think I should be making interest into a property stimulus just as negative, reflection and rotation are stimuli. Then it should be aggregated with all possible stimuli at all levels of complexity.
Practice versus doing
We obviously do things because we want to achieve a goal that is of interest and we start the action habit consciously but perform it subconsciously. But when we practice what is the motivation. It may be that the action habit has yet to find its lowest level common denominator trigger and or goal object type / stimulus aggregation. We practice action sequences many times until we have them right. What do I mean by "right"? It is the feeling that the habit does not need any more improvement. It is a successful one that always achieves the goal.
So how might this work? Given a single sense with two properties such as colour and size we could experience any combination of these two properties in a stimulus. Let us assume there are 3 colours, red, blue and green, 3 sizes, small medium and big and 3 output actions, a, b, and c. Upon becoming bored with "big red" we perform the response a reflexively. The next stimulus is then "small blue". This generates an action habit "big red" -> a -> "small blue". This action habit is at the most specialized level. If later we again experience "big red" the action habit will be investigated as to the interest in performing it. If "small blue" or either of its parts is interesting we will perform the same action habit. If we get something other than expected we must replace the existing habit with the new one because the rules of the world have changed. If "small blue" and neither of its parts are interesting we may look for a more general habit that has big or red in its trigger that has an interesting goal. However, if later we experience "medium red" and it becomes boring rather than perform a reflexive response we will have a partial match with the "big red" action habit's trigger. Based on this we will start a new action habit with red as the trigger and response a. There is no need to have an interesting goal. Whatever is common in the result with "small blue" will become its goal. If it is just one of the size or colour properties then we have established a more general rule. If we get neither small nor blue in the result we have a more specialized action habit and it will have "medium red" as its trigger.
So when a trigger becomes boring because its past exact match action habit's goal is not interesting or boring then it will chose a partial match action habit with an interesting goal. If it can't find one with an interesting goal then it will practice any partial trigger match habit before trying the next response in the list of reflexive responses. Since real complex experiences are rarely exact matches we end up practising partial match action habits until the final common denominator of trigger and goal stimulus properties is reached.
This approach means there is no redo interest on an action habit. The interest of the goal stimulus drives the decision-making.
Parallel actions
And what about changing from doing two action-habits sequentially to doing them in parallel? We obviously need to do two action habit look-ups (thoughts) after just one experience used as trigger.
26th Oct 2010 Interest as a Stimulus
Interest is NOT a stimulus. It is a property of all stimuli / objects. This is because we pay attention to all the different combinations of properties of objects and these all must have an "interest" property.
28th Oct 2010 Practice
The fact that you have to practice an action habit indicates that you have not learnt it. This means the action habit is just an idea. Thus we must think about the goal before we try the combination (parallel or sequential) of actions to reach it. Read 7th Oct this year. At this point we are in practice mode. So new action habits must first be created in one’s imagination, then attempted. If successful they are reusable learnt action habits that can be done subconsciously. Obviously ones based on more generic objects / properties are successful and appear to be more widely used than one based on specialized situations. This means that the action habits that contain primitive responses are immediately learnt and ready for doing. A-Sequences must first be thought of and then done in practice mode / concentrating and be successful before storing as doable / learnt action habits. This applies to A-Sequences and also partial match to trigger action habits. And I have said before it also applies to creating parallel action habits.
30th Oct 2010 Structure of binon tree
The challenge is to devise a data structure that makes it easy to manipulate and navigate based on all the many ways it is used. Binons provide a compact way of identifying an object made up of two parts, each of which is the same type (property). These form patterns. But when I am dealing with multiple independent properties that have to be combined into a situation / experience, are binons still as efficient? For graduated sensors and graduated readings I have the properties of sense pattern, level, position, size, intensity, shape pattern, rotation, contrast pattern, reflection, and negative. Some of the operations I need to perform are:
- Identify any combination of values for the properties for matching.
- Identify a subset of a combination of properties that are different / changed.
- Pay attention to any combination of the properties and identify what I find. (Find Instead)
- Pay attention to a combination of properties, find it and retrieve its other property values.
- Attach interest to any combination of properties using the rules:
- Interest in both parts makes the whole interesting
- Neutralising the interest in the whole neutralises the interest in the parts
31st Oct 2010 Binon Structure
If binons are used to aggregate (":" = combine) these properties it might look like this for symbolic input. The properties are:
Sym = Symbolic value
Snsr = Sensor
Obj = Object
Sns = Sense
Sit = Situation
The combinations are:
Obj = Snsr : Sym
Obj = Obj : Obj
Sit = Sns : Obj
Sit = Sit : Sit = P-Habits
When a graduated sense (array of sensors) is used the Snsr would be zero. Properties are:
Neg = Negative value
Ref = Reflection value
Ort = Orientation = Neg : Ref
Rdg = Intensity reading
Con = Contrast pattern
Contrast patterns are formed by comparing readings
Con = Rdg : Rdg
Con = Con : Ort
Con = Con : Con
Based on position shapes are formed.
Rot = Rotation
Siz = Size Value
Wid = Width pattern
Shapes are combinations of width patterns
Wid = Siz : Rot
Wid = Wid : Wid
Objects are the combination of the contrast and width patterns (shape)
Pat = Pattern for object
Pat = Wid : Con
These need a position to provide an object for a situation.
Obj = Snsr : Pat
1st Nov 2010 Binon structure
I'm going to try and create an entry in Par() for all the values for the following nine properties for all readings at level 1. Then for all those properties that have changed from the previous frame for each sense I am going to produce the higher-level entries for the combinations of parts and their properties. At each level I am going to combine all possible properties per entry to produce the situation. If the sense is graduated (independent sensors) then the sensor properties will be combined at each level. Each situation will have an interest level that may be Ignore for things with gaps on their ends. Then all the possible combinations of situations per sense will be produced. The nine properties are; Sense (Sns), Position / Sensor (Ssr), Size (Siz), Reading / Symbol (Rdg), Width pattern (Wid), Rotation / Orientation (Rot), Contrast pattern (Con), Negative (Neg) and Reflection (Ref).
Attention can be paid to any of these situations, either automatically because of the interest caused by change or by executing an action habit and performing "Find Instead". Short-term memories will be needed per sense for a graduated sense (dependent sensors) and per sensor for independent sensors.
4th Nov 2010 Attention
If a stimulus comes in from the external world or body it must have been a change in the sensor reading. If it is the same value it is most likely from orienting attention to the senses. So when it comes in the same as the previous value and it has no interest level because it is a repeat then it should be treated as the result of an orienting attention action. This would usually happen when thinking has not produced any other action to perform.
6th Nov 2010 Entire tree
On 23rd Aug 2009 & 16th June 2010 I thought I had to create the entire tree of stimuli even though not all of them had changed. I now realize if attention is directed I need to create what was being attended to as in FindInstead. If I have nothing else to think about and I orient to any stimulus and there is no change only then the entire tree should be generated.
8th Nov 2010 Thoughts on Thoughts
We appear to be able to think about a sequence of ideas / concepts and then combine them into a single parallel idea. Take for example in imagery you are told to put together the letters V, H and Z. One hears these letters sequentially but you create the image VHZ in your mind. You have never ever seen this combination before so it is not based on an experience. But you have experienced the individual letters. Does the same happen with external stimuli? We learn letters in sequence and we see instances of them combined in parallel such as "BAT". We also see multiple views of the same object sequentially but attribute them all to the same object. You see a hammer from all angles and can recreate these in your imagination. This is because given one image we can perform the mental equivalent action of rotating and get the associated image. But the aggregation of sequential stimuli into one parallel stimulus is not such an obvious external stimuli action.
Interest reduction
When we are expecting a P-Habit stimulus and only one of the 2 parts occurs we are left with the other part because it is interesting. Its interest was not reduced by the expectation. We therefore pay attention to that part and thus have reflexively performed the orient attention action to the part of a P-Habit stimulus. This means that interest in external stimuli must be reduced for any matching parts of the expected goal even if we did not match the whole goal.
10th Nov, 2010 Action selection
An alternative strategy described on the 11th Feb 2008 for selecting reflexive responses would be to cycle through a single series whenever a reflexive response is needed. I would not have to keep a record of the last tried action per trigger stimulus; just a single last tried action. If the one chosen happens to be the same as the last one tried for the trigger stimulus then it could be skipped and the next one tried. This would mean that Adaptron might never get around to trying all possible actions in all possible situations i.e. an exhaustive search. But given partial matching of trigger stimuli it would try actions that have a possibility of reward. Reward is novelty in the current system. As well no stimuli would ever become permanent.
Since independent objects change independently they are interesting at different times and possibly attract attention at different times. Thus actions tried reflexively will be ultimately attached to the most general objects (parts (or concepts/ features) of wholes that are independent objects). As new specialized situations occur a subset of the parts that have changed in the situation attract attention. If this specialized subset is new then there will be no known action to perform. However, if any of its parts have learnt action habits then these can be performed. Read 2nd July 2010.
Right now Adaptron only does partial trigger matching for finding action habits to do on the 1st layer of the two parts comprising the trigger. This should be done down to the lowest level of independent parts. And rather than doing it after the situation tree has been built and the attended to stimulus decided these partial trigger matches could be collected as the situation tree is being built. The highest level partial trigger match would then be used.
What happens when we add the creation and storage of expectations? For performing learnt action habits there is no stored expectation. The goal is interesting and we start the habit executing subconsciously. Expectations only occur when there is thinking involved and thinking about what to do means we will be practising a habit, not doing it subconsciously. When learnt partial match action habits are started for all the parts of the situation that are familiar there may remain a part of the situation which is unfamiliar. This is the piece that would be thought about. For example with 3 senses and the change on these 3 senses creates ABC. Each letter represents a different sense's reading. A and B have action habits with interesting goals and these habits are started. C has some action habits but no interesting goals. We think about C to discover possible action sequences. We explore C by doing any possible actions that will get an interesting goal. We may learn an action habit for C that produces an interesting goal.
In this way we build up a collection of action habits that are triggered by the most general parts of a situation. These are the lowest level independent features / concepts that can be combined to form a situation. But how does specialization work against this and stop it from becoming too general? How do we learn that the colour blue is not always to be followed by a certain action? How do we learn that it is irrelevant in the action selection? On the 2nd July 2010 I use the example of smooth objects being touched. Then touching a particular smooth object is not rewarded. If we were punished then this would produce fear if emotional feelings were implemented. And the fear would be propagated to all the parts of the situation including the smooth property. But what if it were not punished but just lost its reward? Then the goal stimulus would lose its interest and the learnt action habit would not have an interesting / rewarding goal. So it would not be started subconsciously. However if the action habit were combined into an A-Sequence it would no longer be the goal stimulus of the touching that initiates the action habit but the interest in the higher-level action habit's goal.
Binon Structure
I need to make the binon structure more generic such that the property combination and the value combination for a situation are separate until they are finally joined at the highest level to produce a situation. This would mean that for Senses I need a property tree that has sense objects composed of sense objects which are finally composed of the lowest level 1 Sense objects. Then I also need a sense value pattern that provides the combination of sense numbers. I would do the same for sensors. The Sensor property combination would be a sensor object tree while the Sensor value combination would be the sensor number pattern. A symbolic stimulus on several sensors across several senses would then consist of a stimulus property combo and stimulus value combo. The stimulus property combo would be the sensor property object combined with a reading combo property object. Then these combined with a sense property combo. The stimulus value combo would be the same topological structure but only have value objects in it.
9th Dec 2010 Dynamic tree creation
In attempting to save space I have limited the STM entries for P-Habits to just enough for combining one experience from each sense based on sensor number 1. This means that when there are 2 or more sensors for a sense with independent sensors the different combinations of sensors are put in the same STM entry for sensor number 1. Each cycle the most interesting combination of sensors in a sense or all the sensors if there is no change is chosen as that sense's experience. The sensor STM entries are all pre-allocated and all created whether they are interesting or not. However the final P-Habit experience which consists of the Source value (external perception or internal thought) and Situation object (Sense where pattern & Sense object experienced) must contain the correct Sense where pattern based on the correct sensor combination and not based on sensor number 1. Thus given a P-Habit experience in an A-Habit the STM entry is complex to find. When FindInstead is given a P-Habit experience to find it can recreate the new stimulus and place it in the STM entries correctly because it is a bottom up creation process. A-habit execution also has to neutralise the interest in experiences before the most interesting remaining experience can attract attention.
If I was to create the tree of experiences dynamically based on interest level and modify the interest dynamically at the same time based on action habit expectations I would be left with the most interesting remaining experience. I would then recreate the experience from the raw data for FindInstead. Read 23rd Aug 2009. I would still have to create the entire tree to find any experiences that are interesting not because they changed but from their interest level in memory. This tree though does not have to be saved, just created and memory interest levels checked dynamically.
Dynamically creating these higher level experiences and not keeping the intermediate ones in the process also has ramification in forming S-Habits. Currently I have a fixed STM for each sensor combination in each sense. In a dynamic architecture I would only keep STMs for sensor combinations that change from one cycle to the next. I would also have to dynamically allocate space for them and search it every time I wanted to add another stimulus in sequence.
10th Dec 2010 Interest propagation
Interest must be propagated backwards to the trigger when an action habit gets an interesting goal. For example a penny has no intrinsic value but it does because of actions that involve it obtain a valuable goal. The same happens to plastic tokens which can be swapped for pennies or a click given each time something is done correctly for a trainer and was associated with a reward. The interesting trigger retains its value until it has an undesirable goal. And we don't have to check our memory of action habits done to determine the trigger's interest level. (Read 4th July 1999, 10th Jan. 2004, 31st July 2006, and 28th Aug. 2006). On 6th Oct. 2007 I recorded some ideas about it. Note that the goal was the stimulus that generated the actual interest stimulus. The trigger does not generate interest. It has an expectation of interest.
If the memory of a stimulus has an expectation interest level and that stimulus is perceived what would happen? When it is perceived it causes a change from the previous perception and will have 'change' interest as a result. An action habit expecting it would neutralise the change interest. But its expectation interest would still exist. And if all change interest has been neutralized we would therefore pay attention to this stimulus because of its expectation interest. I used to have the same idea with some code to pay attention to any trigger stimulus that had a redo-interest. When attention is paid to this expected interest trigger, if its interesting goal still exists that action habit will be done. If the action produces interest then the trigger's expected interest is retained. However, if the action gets its expected goal this goal will be of neutral interest and the trigger's expected interest will be neutral.
But the power of expected interest is that if a goal is obtained with expected interest then the trigger gains this expected interest.
11th Dec 2010 Practiced A-Habits
When past experiences are being practiced what happens when the final expected goal is not obtained but something else occurs instead? For example I have AxB and ByC where A, B, and C are stimuli and x and y are responses. C might be interesting but not B. We perceive A and think about the possibility of getting C. We do the x at concentration level and get the B. We do the y while concentrating and create a new A-sequence response z = xBy. We get a goal of D instead of the expected C. FindInstead obtains the D. It may or may not be interesting. However we do want to update our action experience history. We could save AzD and / or ByD. Save AzD for sure because we were practising the z response. And save ByD too because this is how the world now works instead of ByC.
Thinking loop
I want to restructure the algorithm to include a loop that performs action habits that include attention to thoughts. I need to create thought stimuli as well. The current algorithm does:
- Get stimuli
- Execute all action habits to reduce interest level
- Pay attention to interesting stimulus or expected goal
- Record action habits based on attended to stimulus as the goal
- React to boredom and do dependent sequence recognition if attended to is dependent
- Determine next action (currently includes thinking)
- Do next action
Step 6 will now have to create a thought action habit with the expectation (thought) as a goal. Essentially it would go back up to 1 and get the in memory stimulus, skip 2 and do 3 on the recalled thought. It would do 4 to record the thought action habit.
In more detail these steps would be:
At 6 find the most interesting goal of an action habit associated with the attended to stimulus. A stimulus with actual interest would be more interesting than one with the expectation of interest. A stimulus with actual interest would have to be an external stimulus. There would be a reflexive orienting thought action of the interesting stimulus as step 7. This would be equivalent to doing 3 on the associated expected goal and 4 to record the reflexive thought action.
Then this thought would be the attended to stimulus. But it would be matched against the memory of real world stimuli in 6 to determine the next action habit. As long as there are goals of action habits with expectations of interest this should continue. As soon as there is a goal with actual interest then real world actions would be done. But we don't want to do the 3, 4, 6 cycle for a real world goal with actual interest. This situation should just associate expected interest with the attended to stimulus. Then the thought of the expected goal is only produced in the 3, 4, 6 cycle when there is expected interest.
But how do we repeat thought actions non-reflexively. Do partial matches with experiences trigger them when there are no expected goals with real interest? Is this how we can execute a thought orientation action habit and not get a matching goal thought from memory? And when we do two or more orienting thought actions we produce an STM of these thoughts. If we do two thought actions in a row do we then have thought action sequences?
12th Dec 2010 Thinking
Learnt thinking actions can be performed subconsciously. I have counted subconsciously from 1 up to 64 when doing my exercises while thinking about a different subject. There is a subconscious inner voice taking place.
Following on from the 8th Nov 2010 in which I mention how a sequence of thought images can be combined into a single parallel image. When we are observing something moving or rotating we perceive a sequential stream of images from the same object which we understand to be the same object. Obviously those properties that are constant during change must be fundamental to the object. But given rotation we could end up with one side having nothing in common to the first side. But we would have a sequence of changes progressing from one side to the other and maybe we have an S-Habit that identifies the object.
13th Dec 2010 Sequence to Parallel transformation
More about 8th Nov 2010. Obviously we can aggregate sequential mental images into one simultaneous image and also decompose a composite imagination into its parts sequentially. However there are some rules that must be followed. An image may block or partially obscure another image according to the rules that our sensors observe. We can hear in our inner voice a tone and add a second tone to it to get a chord but cannot hear two tones of the same frequency at different volumes. We cannot imagine a black square on top of an identical yellow square in parallel. Translating this into design means that if B and C are from sense #1 and X and Y are from sense #2 we can take the sequence B, Y and form the P-Habit B:Y. However we could not take the sequence B, C and form B:C because it is not possible. This means that STMs should be able to aggregate their stimuli to form P-Habits even though they are out of synch sequentially. Is this not what happens in the following using the same senses and stimuli above?
Order: 1 2 3 4
Sense #1: _ B B B
Sense #2: _ _ Y Y
Attention to: _: _ B Y B:Y
When a change happens, attention is attracted at 2 and 3. And when no change happens at 4, we perceive the whole. However the mental imagery feels like it adds Y to the existing B and does not do step 3. Mind you it takes place so quickly it is hard to know. If you were given the stimuli verbally as in, think of a cat beside a book, you would perceive the two separately first because you have to convert the sound of the word cat into an image. So when we think about the 2, 3, 4 sequence and then reapply that to different stimuli we end up creating in our imagination something that we may never have actually experienced. Note that the content of the sense #1 imagination STM must retain the B idea while the sense #2 STM obtains the idea of Y.
New algorithm
The new algorithm needs to include the 11th Dec steps 3, 4, 5 and 6 in a loop until the next action to perform is an external response and not a thinking orienting response. For a thinking cycle step 3 would start by paying attention to any interesting idea or an expected idea goal if it was performing a thinking action. Step 4 would record a thinking action habit. Step 5 may do dependent sequence recognition if the thinking being done is the rehearsal of a sequence such as trying to remember a phone number in the short term.
Types of Thinking
There are several types of thinking processes that all share the same underlying mechanisms. Types of thinking include:
- Remembering a sequence of past events.
- Forming an imaginary combination of ideas or decomposing one.
- Attending to a feature (more generic property) or combination of features (more specialized object) of a memory.
- Thinking through a sequence of actions as in planning. Probably starts with type 2 as a goal and is followed by problem solving thinking in order to find the action to perform to achieve the goal. (Read 26th April 2003, 6th July 2003, and 6th Oct, 2007)
- Associating an idea (imagery or inner speech) with a word or vice versa. Done as we listen and speak or read and write.
- Reminding ourselves of a future goal / action to be done (Read 18th Oct 2010).
- Running through a scenario / plan in your mind to predict what might happen and how you would deal with it. A variation on 4. - Planning. A sequence of 6. - Reminders
- Dreaming.
- Memorization / rehearsal of a sequence.
- Tip of the tongue upon retrieval attempt. You know you know the answer but memory is not retrieving it.
- Know that you don't know the answer to a memory retrieval.
- During the performance of a plan the goal is kept in mind. - Concentration as in practising. If it is a multi-step plan then is there a hierarchy of goals and sub-goals?
- Induction - concept forming from examples. Drawing a general conclusion from a number of known facts. Finding the common concept of two thoughts. Related to 3. Daisy is a swan and white, Danny is a swan and white, and Dante is a swan and white. Therefore, all swans are white.
- Deduction - reasoning from facts to form a conclusion as in 7 or reasoning backwards as to what must have been the cause. Reasoning from the general to the particular. Inference: forming conclusions from premises. Related to 3. Example; All swans are white and Daisy is a swan. Therefore, Daisy is white.
15th Dec 2010 Resetting Interest
For some time now I have been using the strategy of neutralising the interest in an interesting goal stimulus (1st goal) at the time I start doing the action habit. The idea is that if the next experienced goal is the same as expected then it will be neutralised anyway. And if the next goal is different (2nd goal) from the expected this new goal will be interesting instead. And when this 2nd goal becomes neutral I don't want the original 1st goal to remain interesting else I will continue to do the past action until the original 1st goal becomes neutral. This may never happen if the new 2nd goal is the new state of the world.
Now I am rethinking this strategy. If I were to leave the original 1st goal interesting and continued to do the action habit expecting it when I get the new 2nd goal instead I could reduce its interest from interesting to neutral and on the next occurrence from neutral to boring. Since the boring interest on the 2nd goal would be more recent than the interesting level of interest on the 1st goal I could then trigger a reflexive action for the given trigger stimulus.
The implementation challenge with this new strategy is to reduce the interest in the 2nd goal when the action habit being performed is the one expecting the 1st goal. One strategy is to run both action habits in parallel each expecting its goal as long as they are doing the same response. If the experienced goal is the 1st goal then this one gets reduced to neutral interest and the other one fails. If the experienced goal is the 2nd goal then this one gets reduced to boring because it had an expected interest of neutral and the other action habit fails. The more recent 2nd goal is then boring and the action habit would not repeat the action should the trigger happen again.
Would this work better if thinking were taking place and expected interest were involved? Running both habits in parallel would imply that both goals are expected. The second time the trigger happens a thought action habit would form with the perception as the trigger and the thought about expected 1st goal and its expected interest as the goal. Then a second action habit would form with the thought about 1st goal as the trigger and the 1st goal as perceived the goal when it is perceived.
For example, A and B are stimuli and x is the response. A is perceived for the first time and reflex action x is performed. Goal stimulus B is perceived and action sequence AxB is formed. B is set to interesting because of the change experienced and no expectation or action habit was in place.
A happens for the second time. The thought is of B and its interest. These are labelled Be and Je standing for B expected and J expected respectively. So now a thought action habit is formed and remembered. It is A_Be:Je where the underscore is the pay attention with no physical response. The AxB action is started and gets performed. B is experienced. The previous conscious stimulus was Be so now a thought action habit is formed and remembered. It is Be x B and B is now neutral in interest. However Be still has expected interest.
A happens for the third time. AxB has no expected interest because B is neutral so it is not thought about. Instead A_Be has expected interest and is done as the thought action habit. Be is attended to and the Be x B action habit is thought about. The expected B goal has no interest and thus Be's expected interest is now also neutral. Thus the only thing left to do is try a different reflexive response.
In these sequences the structures that are formed and the rules applied are as follows. Let P stand for a perceived stimulus and let T stand for an expected stimulus (thought about, idea, notion, imagery, inner speech etc.). Let r stand for a physical response and underscore stand for the pay attention orienting response to whatever is the goal stimulus. First time experiences with no expectations take the form of PrP or P_P action habits. A second and subsequent time experience forms P_T and either TrP or T_P thought action habits. Also multiple T_T thought action habits could form the third and subsequent times should the trigger thought have an interesting perceived goal. Both Ps and Ts would have associated interest. When a P has interest it is its expected interest from its most recent occurrence perceived. The interest associated with a T is its expected interest from the most recent thought about P in a TrP or T_P action habit or the most recent T_T action habit. Thus expected interest propagates backwards to the trigger of thought action habits when they are done. Neutral interest should also propagate backwards in this way. P interest does not propagate backwards the same way as this over PrP action habits. Thus dynamite is not painful but the idea of dynamite has expected pain (fear) associated with it.
Interest and Expected Interest
The interest stored with a P is actually expected interest as is the P an expected P because they represent reality. Only the actual physical stimulus is a P and only it can cause real interest. And thus boredom is an expectation only. Real physical stimuli are either interesting or neutral. They don't generate boredom; they just habituate.
So what is the real distinction between a T and a P? Ps originate from the senses and get stored in memory as Ts. Then Ts originate from memory when recalled and are stored back in memory as Ts. A P when experienced matches with stored ones in the form of Ts. Then how do we distinguish between a P_P, P_T, T_P and T_T action habit? Obviously the distinction is in the attention paying action. The P_P and T_P use a pay attention to senses action while the P_T and T_T use a pay attention to memory action. The pay attention to memory action then uses the where information on the goal T to identify what to retrieve from memory. And it is only this action which causes interest to propagate backwards.
This now means I must remove the external value object from experiences in my model because the source of a memory is not part of the memory. However this contradicts the feeling we have that we can distinguish between memories of experiences and memories of thoughts. So let's correct the previous paragraph. Ps originate from the senses as stimuli and get stored in memory as Ps. Then Ts originate as a recall of a P goal from memory when performing the pay attention to memory action and they are stored as Ts. A P when experienced matches with stored Ps.
However when we pay attention to a thought it is only matched against stored Ps as triggers of action habits. So this generates the question, can you recall a thought or do you have to regenerate them from Ps? I believe you regenerate them from the Ps by performing P_T or T_T actions. In the T_T and T_P scenarios the trigger thought is matched against stored P's. This would mean that TrP, T_Ts and T_Ps action sequences should not be formed. T's can only exist as goals of thought action habits. However they must be combinable and combined according to the laws of P-Habits and conscious STM to form thoughts without any physical real world counterpart. Thus only PrP, P_P, P_T are kept. This would mean that the Be x B action habit is not valid. However one can perform multiple P_Ts in a row, each one of which the T matches with a stored P. When that stored P matches it could trigger another P_T. In this way a series of Ts become conscious and can be combined.
How does the AxB work with these rules? A happens for the second time. The thought is of B and its interest. So now a thought action habit is formed and remembered. It is A_Be. Be is given an expected interest. The AxB action is started and gets performed. B is experienced and is now neutral in interest. However, Be still has expected interest.
A happens for the third time. AxB is not thought about because B is neutral. Instead A_Be is done as a thought action habit because Be is interesting. Be is attended to and it matches any action habit that has B as the trigger. This forms a B_T thought action habit. If it has an interesting goal we would start practising the AxB and B?T action sequence. However if there is no interesting B triggered action habit, Be becomes neutral because the T is neutral. Thus the only thing left to do is try a different reflexive response. But at this point the thought sequence has been Be and T. Is this what is in conscious STM? Do I form a thought sequence from it? Maybe only if the two are from the same sense.
Now I also must think about how this would work when the second time the goal stimulus is not a B but a C because the world has changed.
16th Dec 2010 Bored of results
So given the action habit AxB with B having an interest, A happens for a second time. We perform the x and get an unexpected C. We now have two action habits (AxB and AxC), both with the same response and an interesting goal stimulus. We also have the thought action habit A_Be with Be having expected interest. A happens for the third time. We reflexively create the thought action habit A_Ce with expected interest for Ce. We start both action habits and perform the x response. We don't perform the A_Be thought because it only has expected interest. We get the C expected stimulus. Interest in C is reduced to neutral. A happens for the fourth time. B is still interesting so we reflexively perform the A_Be thought action habit and start both action habits and perform the x response. The AxB action habit is expecting an interesting B while the AxC action habit is expecting a neutral C. We get the C stimulus. But now how does the C become boring so the habit AxC does not get done again and overpowers the desire to do the AxB habit because B is still interesting? It would appear that the expected interest is reduced by the actual interest rather than the other way around. Would this be true if emotional feelings were involved? No. Emotional feelings associated with stimuli are based on the most recently experienced feeling. The expected interest being reduced by the actual interest is based on the idea that the habits expect a repeat of the goal stimulus and we are consciously trying to avoid repetition. If the C is novel and it repeats then it becomes neutral and not wanted again. If it is not wanted / not neutral and it repeats then it becomes boring. So then C is flagged as boring which means avoid experiencing it again, i.e. avoid repeating it. The next time the A occurs the more recent AxC with a boring C will cause the reflexive A_Ce thought. Ce will get an expected boring interest level. The response will then be a reflexive one.
Avoid repetition
If the true pure objective of Adaptron with only the change as a reward is to pursue novelty and avoid repetition then the 1st occurrence of a stimulus should be interesting and the second and subsequent occurrences should be uninteresting. This would mean that on each subsequent occurrence of a stimulus it would always reflexively try a new response. The stimulus would start out as neutral and become interesting on its 1st occurrence. If a habit has it as a goal then that habit would be repeated to achieve the goal. If the goal is achieved the stimulus would then be uninteresting. Even if the stimulus causes change when it is next experienced it would not become interesting. The idea is that it is not novel. Eventually all possible responses will have been tried for the stimulus and it will become permanent. Now it will be incorporated into S-habit sequences.
Change versus Interest
The above analysis implies that change is not the same as conscious interest. Change occurs as stimuli are perceived and it is used to attract attention. However interest is based on and determined at the time of conscious attention to the stimulus.
17th Dec 2010 2nd time Bored
I've just changed all the test cases up to #19 such that when a stimulus is first conscious it is interesting and on the 2nd and subsequent experiences it becomes boring. The thinking turned-on test cases are the same as no thinking because on a second occurrence there is a reflexive reaction to the boring stimulus and no chance to repeat or think about any learnt habits. I'm now going to try a strategy where the interest level goes from interesting to neutral and then to boring on the 3rd occurrence. This will be a little less reactive.
It now waits and repeats the orienting response on the 2nd occurrence of a stimulus. But once it gets the 3rd repeat of a stimulus it once again does no thinking, just tries all the other responses reflexively. However with thinking turned on it now reacts to the second A in a row as in test case #14. Without thinking it waits for the 3rd A in a row as in test cases #1 and #13. That is because with thinking turned on it reacts reflexively if the thought is neutral.
Maybe I should turn off the reaction to the 3rd conscious occurrence. Or maybe I should implement thinking as above because expectations of interest last a while after loss of actual interest.
18th Dec 2010 Reacting to boredom
We do not perform reactive behaviour just because we have experienced a stimulus 2 or more times. We just become uninterested and this does not trigger a reaction like we have for a painful event. So uninteresting means neutral interest and this allows for partial matching and thinking to take place. We choose a reflexive response only after these have failed to provide an action to do. This is when boredom occurs.
Action Selection order
I need to sort out the order of action selection. Currently I have:
If attended to stimulus = boring then React (must be permanent)
Else if it's dependent then do nothing - go round get next stimulus (orient?)
Else if it's independent
If novel (no action habits) then orient response
Else have action habit
If interesting goal then do it
Else if boring goal then do reflexive response
Else if neutral goal then partial match check
If interesting partial match then do it
Else if not concentrating and not thinking do reflexive response
End if
If thinking and no do it or response then
If interesting thought then do it
Else if not concentrating then do reflexive response
End if
End if
End if
The internals of this should be straightened out.
If the attended to stimulus is independent and has an action habit then
Step 1.
If interesting goal then
Record P_T, assign Ie to T and do action
Else (neutral or boring (must be permanent) goal) then
Perform partial match of attended to stimulus
If partial match has interesting goal then
Record P_T, assign Ie to T and do action
Else if attended to stimulus has a thought action habit then
If expected interesting goal then
Perform thought match with memory and
Attend to recalled stimulus - continue at step 2.
End if
Else
Do a reflexive response
End if
End if
End if
There are two places in this algorithm where a thought habit (P_T) is created reflexively and one where an existing thought habit is repeated from memory. It does not take into account the situation when concentration is happening.
Goals and Sub-goals
I have previously decided to only set the concentration level to interesting when practising a sequence of two learnt action habits that had been thought about and the second had an interesting goal. There is an intermediate sub-goal to be reached by the first action habit that was uninteresting and a final goal to be reached by the second habit. But I still feel that concentration is required when performing an action habit for the first time, when the goal stimulus is interesting and only one step is required. There is no sub-goal in this scenario. What if I had thought through a multi-step (greater than 2 steps) plan? Each step would be thought about as a thought habit and would be the most recent habit for the given trigger stimulus. In a way we are reminding ourselves of the actions to perform in the series of situations we will find ourselves as we do the action sequence. But each thought habit to act as a reminder must have a goal thought with the expectation of interest. This would imply that all of the goal thoughts of the thought habits are given the expectation of interest when the last thought about habit reaches an interesting goal. If we just consider the 2-step thought habit sequence the first thought about goal could be in conscious STM when the second thought about goal is added. At this point the first could gain its expectation of interest from the second.
19th Dec 2010 Concentration
I'm starting to question the use of a concentration level to stop less important stimuli from interrupting a habit that is being learnt. Isn't everything we do started consciously with a desire to do it? Many things are done subconsciously but they still have a goal worth accomplishing. So the interest level in the goal must be interesting to start a habit. So this can't be used to set the concentration level. I'm also using concentration to allow two thought about habits combine their responses and intermediate stimulus. This probably can be done as long as the 1st habit gets its expected goal. And this is what is important. I believe we have at any one time only one conscious goal. When it is reached we think about the next goal and start the appropriate habit. And if accomplishing one goal takes a lot of steps it is possible for it to be interrupted by another habit with the same expectation of goal interest. This is how we may end up learning to do two actions in parallel. This is now working. All action habits are being done at the same level. They get interrupted when they are unsuccessful in predicting and reducing the changes that come from the senses. And two successful action habits in a row create an action sequence.
20th Dec 2010 Binon structure
I've realized that the best structure for binons is that every situation is made up of two parts. The 1st is the Identity, Address or 'where' information and the second is the Value information. At the sense level of complexity each situation is made up of the sense pattern (Where) and the sense value pattern. For example on Sense #1 there is the value B and on Sense #3 there is the Value X. At the single sense level the two situations are 1,B and 3,X. At the pair level the situation is made up of the 1:3 sense where pattern combined with the B:X value pattern. The Value pattern does not tell you anything about the senses on which it is found and could be reused with other sense where patterns. The same structure applies to independent sensors. But if they are to be combined across senses then each sensor needs a two-part identity, sense and sensor number. For pairs and higher levels of sensor combinations the two-part identity would be sense number and sensor where pattern. Given sensors b and e with readings of F and J of sense #1 and sensors b and c with readings B and D of sense #3 the following combinations would be created. 1b, 1e, 3b and 3c sensor where patterns at the 1st level sensor identity. 1:(b:e) and 3:(b:c) at the 2nd level. The b:e and b:c objects could be reused across senses. At the pair or senses level the identity would be (1:3):((b:e):(b:c)). The sensor value pair patterns are F:J and B:D. At the sense level the value pattern becomes (F:J):(B:D).
If this same approach is to be used for width / shape we have to decide which part is the relative width pattern. Is it the identity or the value? I would say the relative width pattern identifies the shape independent of its size and rotation. Thus for dependent sensors the shape identity must be the sense and relative width pattern. The shape value however must contain something about the size and rotation. The size value could be a single integer for the shape. The rotation however is a rotation value pattern. Here is an example for Sense #4 with a shape made up of widths 1:3:5. The relative width pairs are 1:3 and 3:5. Combine these with the sense to produce a sense specific identity and you get 4:(1:3) and 4:(3:5) at the pair level. At the next level it is 4:((1:3):(3:5)). The value parts to go with these are 4 and 8 at the pair level and 9 at the next level. The rotations are both positive. For the threesome the rotation is 1:1 where 1 is a positive rotation. The width combination 5:15:9 would have a rotation pattern of 1:0 where 0 is a negative rotation, i.e. 5:3 width ratio rather than 3:5. The width combination 15:5:3 would have a rotation pattern of (0:0) and 9:3:5 a rotation pattern of (0:1).
However, this structure requires decomposing the where information and the value information in parallel and combining their parts to get the next level down combinations. It might be worthwhile to keep the where and value parts together when creating the next level higher value part and then attaching a pure where/identity for that level. Thus whenever a value part is decomposed it contains two parts each of which has its where and value part.
22nd Dec 2010 Recency
I have decided that if I have an old A_B habit and a more recent A_C habit as in test case #8 then only the most recent action habit is used for expectations that reduce the change in the goal stimulus the next time the trigger A happens. Even though the B is interesting the recency of the rules of the world are expected to be more powerful. I'm going to try this out and see what happens.
24th Dec 2010 Thought Action Habit
Maybe we don't need to create a P_T thought action habit. Maybe we only need to create the expectation / thought and its associated interest. Then these thoughts get combined in the conscious STM? The thinking orienting response that is in the P_T may be automatic and always take place for every P. And it may be interrupted by an interesting thought that initiates an action habit.
Thinking
We decide to do something either because the goal is wanted or the idea of the goal is wanted. Assume we have an action habit PxGj where P is a perception, x is the response, G is the Goal perception and the j is its positive interest. When the second time P happens we should automatically generate and remember Gej expected goal with an interest j before doing the x response. Assuming the G goal is repeated its interest will become neutral but the Ge's interest will be positive.
We could then create an action habit triggered by this Ge such as Ge x G (provided the required G occurs). This Ge x G is needed so that the next time we think of a Ge and this idea of the goal is wanted we know what to do. Ge will remain interesting and become neutral only when G is recalled. This would happen on the third occurrence of P.
When the third P occurs, G will be recalled and Ge will become neutral. However should there be an action habit with G as the trigger and a goal stimulus S the Ge thought will match with the G trigger. If S is interesting then Ge would regain interest and the Ge x G action could be done. If however S is neutral the Se thought could be generated and thus a train of thoughts produced.