
2014
3rd Jan 2014 Action Habits
4th Jan 2014 Action Habits
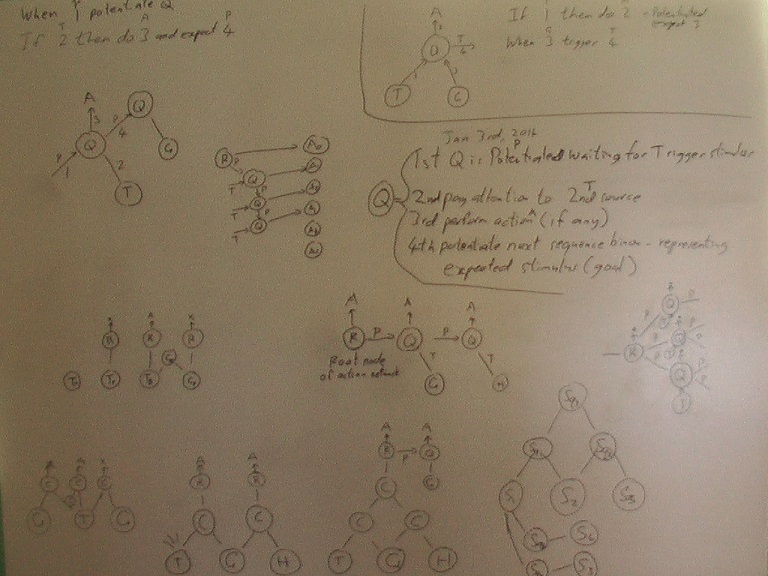
I have been using my new whiteboard to work out different configurations of action habits to try and sort out how they should function, consciously and subconsciously. The basic acton should be a node that corresponds to the "If stimulus Then action" production rule.
act
↑ 3
p1 → Acton p4 →
↑ 2
stimulus
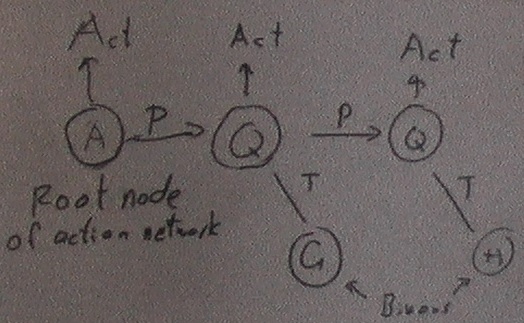
When being done subconsciously, it needs to be potentiated / primed into the state in which it is waiting for / expecting the stimulus. This is done by p1. When it occurs, the stimulus then fires the acton at 2. The acton then fires the act at 3 and may prime (p4) a next action habit / acton. As a root acton it can be fired by 2 without having to be primed. This is how it is connected to binons / stimuli for conscious execution. We think about the stimulus and its associated goal and start performing the acton by firing it. The act fired by 3 can be zero or more actons or primitive acts that are fired in parallel. The acton primes, via p4, zero or more next actons. These next actons will all be waiting in parallel for their firing stimulus. The acton may prime no next acton in which case it is at the end of the action habit sequence. The act can also be the act of doing nothing, (no act fired by 3) in which case the result is to prime the next acton that is then expecting the next stimulus. This is equivalent to paying attention without any action. Creation of S-Habit takes place in parallel with acton execution.
7th Jan 2014 Three Sequence mechanisms
While trying to implement the above action habit structure I have come up with too many puzzling questions. The structure does not lend itself to easy navigation from a trigger stimulus to a goal stimulus via a single acton. Two actons are required; one to perform the act at 3 and another that gets primed by p4 that is waiting for the goal stimulus. I require a single node / neuron that is fired by the trigger, performs / fires the act and is then primed/waiting for the goal stimulus. Thus I believe I need 3 different structures that involve sequence. 1/ S-Habits for recognition of sequences of stimuli (such as in Wernicke's area), 2/ consciously executable action habits as described in this paragraph (such as in the motor cortex) and 3/ actons as described on the 4th Jan 2014 for subconscious action habit execution (such as in the cerebellum).
The challenge is to understand and model / implement how the 2nd and 3rd structures are formed and used. I suspect the 3rd structure is created in parallel with the 2nd but must be referenced by the 2nd when a complex activity is started but done subconsciously. To help in the clarity of the discussion I will call the 2nd type Actons and the 3rd type Servons (Do-ons = Duons, Automatons, or some other name I have yet to invent).
In the 2nd structure, the actons, as described as early as 9th Oct 2010, are associated to two binons; the trigger and goal binons.
act
↑
Acton
/ \
/ \
Trigger Goal
There may be no act, in which case attention is only paid to the Goal stimulus. If there is an act then it is done after the Trigger and before attending to the Goal. The act could be a primitive device action or a root servon. A root servon does not need to be primed; it is just fired by a stimulus. The acton has a redo-interest that is used to determine whether it needs to be practiced (novel) or is learnt (familiar).
The normal order in which this structure is formed and used is:
- The trigger stimulus occurs and its binon is created as novel
- The "incomplete" acton is created to represent what is going to happen next
- The act for the acton is to do nothing
- The acton is primed expecting a goal stimulus
- The attention is attracted to a goal stimulus
- The acton becomes novel and associated with the goal stimulus
- At some time later the trigger stimulus occurs again, is conscious and its binon becomes familiar
- The trigger's most recent acton is thought about
a. If this acton is novel then it will be practiced
b. If there is no novel acton then familiar ones will be thought about that have novel goals - The acton is fired if it is to be practiced (novel)
- The act for the acton is performed (do nothing)
- The acton is primed expecting the goal stimulus
- Attention is paid to the goal stimulus that occurs
a. If it is not the same as the expected goal stimulus then a new acton is formed as in 6. - The acton becomes familiar / learnt
- At some time later the trigger stimulus occurs again, is conscious and its binon is familiar
- The trigger's most recent acton is thought about
a. There are no associated actons that are novel or that have novel goals
b. There are no learnt actons associated with partial matches (similar to) the trigger - An "incomplete" acton is created to represent what is going to happen next
- The next (or randomly selected) device act or root servon is done/started
a. If a device act is done then go back to step 4.
b. If a root servon is done then it continues subconsciously and more thinking can be done.
If thinking does not produce any desirable actons to practice or goals to reach then go back to monitoring the stimuli that comprise the servon being done. If thinking does produce a desirable acton to practice or goal to reach then start doing it in parallel with the one started in 17.
These steps are very close to what is currently done in Adaptron. However it does not form servons or perform them subconsciously. The above scenario illustrates what is done for the ABABAB sequence. It reacts with an action after the third A occurs. If we go through the scenario for the AAAAA sequence we also get the reaction after the third A.
- The trigger stimulus A occurs and its binon is created as novel
- The "incomplete" acton is created to represent what is going to happen next
- The act for the acton is to do nothing
- The acton is primed expecting a goal stimulus
- The attention is attracted to a goal stimulus of A
- The stimulus binon for A becomes familiar
- The acton becomes novel and associated with this goal stimulus
- The stimulus A is used as a trigger and its most recent acton is thought about
- The acton is novel and is fired, it is to be practiced
- The act for the acton is performed (do nothing)
- The acton is primed expecting the goal stimulus of A
- Attention is paid to the goal stimulus A, which occurs
- The acton becomes familiar / learnt
- The stimulus A is used as a trigger and its most recent acton is thought about
a. There are no associated actons that are novel or that have novel goals - An "incomplete" acton is created to represent what is going to happen next
- The next (or randomly selected) device act or root servon is done/started
a. If a device act is done then go back to step 4.
8th Jan 2014 Hebb's law
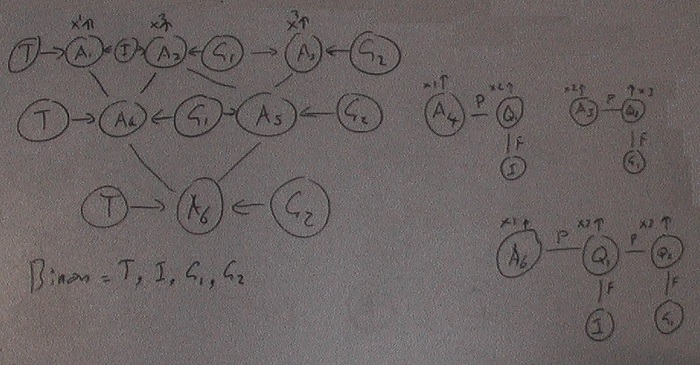
The 1st law that Hebb came up with was about cells that fire together - wire together. It was about post-synaptic coincidence, which is when two cells fire together they are wired together so they are both fired at the same time. This is what I want for combining actons that are done at the same time. I need a common acton that when fired, fires the two sub-actons or slave actons at the same time. It's the process of building up an action hierarchy from the primitive actions that are done in parallel.
A key concept to remember is that a lower level - closer to the device actions - acton can be reused by any number of higher level actons, but an acton can only fire two, either in parallel or series.
10th Jan 2014 Action Types
Action Habits are actually types of actions. For example the action to close or extend a finger is an action type and is independent of any particular finger. Similarly the action type "grasp" is independent of the hand deployed.
Priming and Firing
An action habit that consists of two sub-actions fires one sub-action and primes the second. Given this acton structure the sequence for performing an action habit is as follows:
Trigger --------- Acton #3 ----------- Goal
/ \
Trigger --- Acton #1 Acton #2 ---- Goal
\ /
Inter stimulus
Acton #3 is made up of Acton #1 and Acton #2. Acton #3 is novel and has not been practiced.
- The trigger stimulus occurs and becomes conscious
- The association between the trigger and Acton #3 is traversed by thinking about Acton #3 because it is novel. The thinking may also go as far as the goal via this route to produce the idea of the goal. The result is the decision to perform Acton #3 to practice it.
- The trigger stimulus has stimulated Acton #1 and Acton # 3 such that they are both primed.
- Acton #3 fires Acton #1 (it was already primed) which performs / fires its act (if any).
- Acton #3 primes Acton #2; it is waiting for the Inter stimulus - the feedback stimulus from Acton #2 having performed the act.
- The Inter stimulus occurs and becomes conscious
- Acton #2 is now fired by the Inter stimulus and it performs its act.
- The Goal stimulus occurs and becomes conscious
- The Goal stimulus stimulates / fires Acton #3 which was primed in step 3. Acton #3 has now worked and its redo-interest is changed from novel to familiar.
The Inter stimulus occurring at step 6 will also stimulate Acton #1 but Acton #1 has already fired at step 4 and the result is just to prime Acton #1. If the trigger were to reoccur, Acton #1 would fire at this point.
The Goal stimulus occurring at step 8 will also stimulate Acton #2 but Acton #2 has already fired at step 7 and the result is just to prime Acton #2. If the Inter stimulus were to reoccur, Acton #2 would fire at this point.
It can be seen how an oscillatory / looping action habit / Acton #L can be formed when it is 1st primed and then fired, it performs its act, which produces the goal, which stimulates the Acton #L thus priming it and when its trigger occurs it is fired again. In the case of Acton #1, in order for it to loop, it is primed by the trigger and fired by the Acton #3. In the case of Acton #2, in order for it to loop, it is primed by Acton #3 and fired by the Inter stimulus.
Note that in the steps 1 through 9 Acton #3 does not know it is priming or firing its sub-actons. It is just stimulating them. The individual actons know their state and the first time they are stimulated they are primed and the second time they are stimulated they fire. When they fire they stimulate their entire target actons for which they are the source.
Actons = Binons
In fact an Acton is a Binon. It has two source binons that must both occur, one priming and the second firing it. These are the trigger and goal stimuli for the acton. Then an acton can be linked to zero or more target actons that it stimulates in parallel when it fires. It needs to prime several action habits in parallel to handle all the possible contingencies. These target actons get fired or primed depending on their previous state. For driving graduated devices (ones that take numerical control values) the final actons that fire the devices need to contain ratios of previous and new values because they must represent a change in value rather than an absolute value. This change is the pattern of movement / action rather than the actual action.
Actons also require the same rules for their formation based on them being novel, then interesting and then familiar. And only a new one can be formed from two familiar ones.
13th Jan 2014 Binon states
The familiar binon needs to have three states: Enabled, Neutral and Disabled. When it first becomes familiar it is in the Neutral state. It transitions to the Enabled state when it is first stimulated by one of its two source binons. This stimulation I have been calling priming. If it gets stimulated again by a source binon while it is Enabled then it fires and stimulates all its target binons. It then returns to the Neutral state. If it is Neutral and it is inhibited then it becomes Disabled. If it is Disabled it must be stimulated to become Neutral. A binon also returns back to its Neutral state if it does not get stimulated or inhibited in the next stimulus cycle.
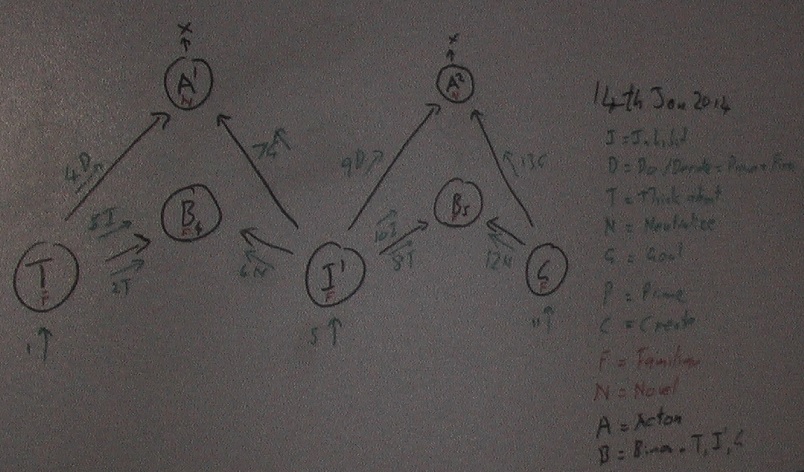
14th Jan 2014 Novel Actons
In the scenario from 10th Jan in step 3 the trigger stimulus is said to fire Acton 3 and then in step 4 Acton 3 fires Acton 1 that was already primed. But what primed Acton 3 such that the trigger fires it. I need a rule that when being created for the first time and when Novel and being practiced before becoming familiar, Actons are fired by their first stimulation. When they become familiar they need a priming and firing sequence. When they are familiar they will be primed when they are stimulated by their trigger and fired by their parent acton. The occurrence of / stimulus from the goal will finish the creation of a novel acton and the changing of a novel acton into a familiar one. But once familiar the goal stimulus will re-prime the acton.
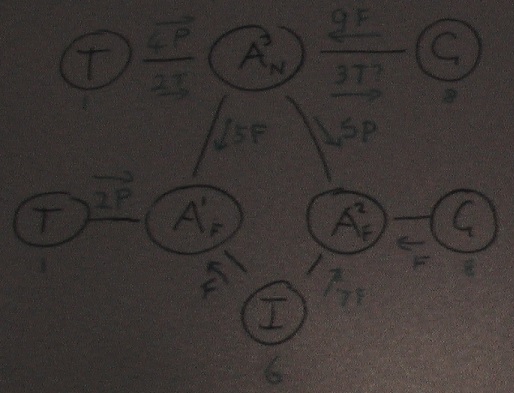
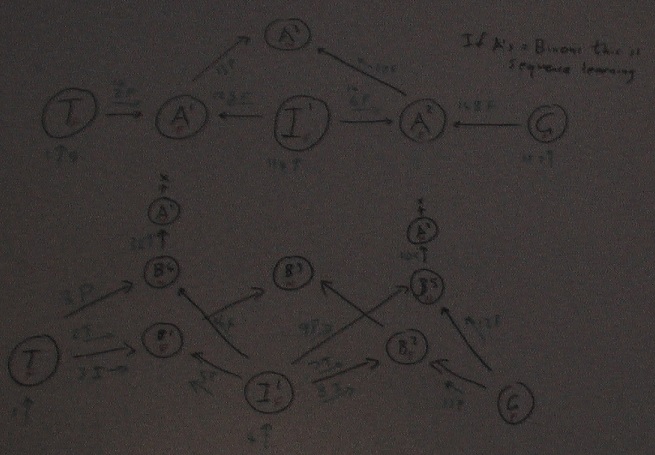
15th Jan 2014 Binons not = Actons
An acton is like a binon but it operates in the opposite direction. It represents a pattern of action, a type of movement. Since all possible patterns must be represented it only has two outputs. By composing actons out of two sub-actons all possible patterns can be represented, just like for the inputs to binons. And the learning / formation of actons can take place like binons when they occur co-incidentally but using Hebb's first law. But an acton can have many input links, be re-used by many higher level actons. So is the concept of priming and firing still relevant for these inputs. Does an acton have many priming input links but only one that can fire it which comes from a recognized binon? The structure of 4th Jan would accommodate this if there were many p1 priming links possible but only one stimulus link 2 that could fire it. From my whiteboard thinking I have decided that if an acton is novel then it can be fired by its trigger binon without being primed. It has no higher level actons to prime it, since it is novel. However familiar actons need to be primed by a higher level acton and stimulated / fired by their one and only one trigger binon. For design purposes it would be nice to have a higher-level acton prime both its lower-level actons at the same time. Given a multi-level acton lattice this would result in all the lowest level actons being primed simultaneously. Then the stimuli would fire these actons and determine the order in which they were done. It would also require that a lower level acton could be primed multiple times from its higher level source actons without firing.
Priming all the lowest level actons in a pattern of action at the beginning of a task allows the order of the stimuli to determine the order of the acts taken. This is necessary when certain events can occur anywhere during a task and you want the appropriate action taken and for it to be taken without conscious interruption. It also allows multiple acts to be done in parallel if their triggering stimuli are available / recognized.
And does an acton automatically re-prime itself after firing just in case a certain event re-occurs during the task? This would also allow for looping activities. If so the acton tree that has been primed must be disabled / neutralized at some point. It would seem obvious to do this once the goal has been consciously reached.
Can a pattern of action be device independent? Patterns of action are types of movement such as grasp with left or right hand, or stretch / close a finger. I don't think so because each device is independent and their sensors form a configuration pattern that is device dependent.
17th Jan 2014 Action Habits
Some thoughts about action habits - may be some repeats. Only kinesthetic stimuli might be used to trigger / fire action habits. This certainly could be true at the lowest level. Action habits are types of actions, motor categories. This is a tough one to believe because they must be tied to device configurations at the lowest level. Action habits are composed of lower level / simpler action habits just as tasks are made up of subtasks. Several action habits get primed in parallel to handle all possible contingencies. Maybe rather than primed the term should be activated such that if they get activated a second time while they are still activated they stay activated (no change in state). The order in which they get done is controlled by the firing of the stimuli that they are expecting. Maybe actons inhibit their expected stimuli so that when they occur they do not attract attention. This does not stop the stimuli from firing the actons.
The order in which action habits get done is something like;
- A goal stimulus is thought about and is desirable. Or an action habit is interesting / new and needs to be repeated / practiced.
- Find familiar action habits to achieve the goal which has a trigger that matches the present situation. This may involve chaining backwards via a sub-goal.
- Start the action habit and inhibit all other goals of actions with this same trigger situation.
- If other goals are thought about and a different action is decided on how does the current action habit get stopped. This will only happen when the current one is being done subconsciously because that is the only way you can be thinking in the first place.
- If alternate actions are selected while practicing they need to replace the original step in the one being practiced.
- If an additional action is started in parallel how does it get combined into the overall action pattern?
- The action-habit is formed when the expected goal is reached. This is the feeling of success. The expected goal must have been conscious during the execution or recognized as the desired stimulus when the action habit completes, for this to occur.
A new idea is that action habits at higher levels are associated with binons at the higher levels. Thus a sequence binon at level 5 (representing five primitive stimuli in a row) is needed to trigger or prime an acton at level 5 (representing five primitive acts in a row).
When we start walking the "avoid obstacle" action habit is primed but it is not done. The sight of the obstacle causes it to fire. It then primes all its sub action habits. These don't get fired until their trigger stimulus occurs.
When an action habit is fired it primes all the next level down sub action habits. There could be many of these that are primed in parallel. Maybe it also has to inhibit some action habit that might cause a conflict on a particular device.
When an action habit affects 2 or more devices in parallel the sensors for these devices will detect a P-Habit comprised of these devices.
Primitive acts should only be done by the lowest level actons. Most likely these actons are triggered by kinesthetic stimuli.
A goal or thought of a goal primes the high level acton and part of the current situation stimulus causes it to fire. It then primes all the next level down actons.
18th Jan 2014 Action Habits
I think I should change my terminology for acton states from enabled/primed, fired/neutral and disabled to just Enabled and Disabled. The goal stimulus enables or activates an acton when it is thought about and the acton is fired to start with by a conscious decision to do so. As long as the goal stays conscious the acton stays enabled and consciously being performed. When an acton is fired it enables all its sub-actons. They are all enabled in parallel. Any that recognize their trigger will fire, enabling their sub-actons. An acton stays enabled after it fires. This provides for looping and re-encountering the same stimulus again during the execution of the action habit. All the actons in the acton tree get disabled when the goal of the top acton is reached or another goal replaces it. Read 22nd July 2011. It says all actons stay enabled until some other acton "takes over" their devices. The goal of an acton is like a set point in process control. Read 11th July 2011 and other notes after it. It says if you want this set point then perform this acton. Read 23rd July 2011, 27th Oct 2011 and 18th Nov 2013 for different types of devices.
Servons
The action habits in the cerebellum (servons) are performed subconsciously. They are fired when their associated conscious acton fires. This acton will be familiar and well-practiced such that all its sub-actons also have subconscious action habits (servons). A servon has no goal. If its firing stimuli are missed, it stops. If a servon is fired consciously to achieve a goal, the goal need not remain conscious because the cortex trusts the servon to reach the goal. When the goal occurs, conscious continuation of the activated / enabled action habit can occur. In between thinking can take place.
Configuration
Given a number of independent devices that can be controlled in any combination the natural way to represent the configuration of devices at any one instance is to use the binary lattice structure of binons. The nodes in this structure would convey firing signals to all the devices on the leaves of the tree. These nodes would not wait for firing stimuli like actons. The node at the top of the tree would represent the configuration. The nodes in the tree could contain values that capture the activation pattern imposed on the devices. Actons would fire the top nodes.
19th Jan 2014 Disabling Actons
I'm trying to devise a strategy and mechanism for disabling / de-potentiating action habits so they are not primed ready for firing by a trigger stimulus. One possibility is to inhibit their triggering stimulus. Thus all actons would remain enabled but just not fired. Another strategy is from the bottom up. For each device, keep track of which acton is controlling it. As soon as another acton is enabled to control it then disable the first. Servons are automatically disabled when they don't get the next stimulus they are expecting. And they expect a stimulus for each cycle in order to carry on. Another approach might be that at least one sub-acton or lower acton must always have fired each cycle for the top action habit to remain enabled. When none of them fire in a cycle then the whole tree is disabled. This is similar to not getting at least one expected trigger stimulus of the activated actons. Or it is similar to getting an unexpected stimulus. If each enabled acton were to inhibit its expected trigger stimulus then any unexpected stimulus could attract attention. This would then result in the activated acton tree being disabled.
Types of actions
Grasping is a type of action, a category of movement. The left or the right hand can do it. But do action habits represent types of actions? I would suggest they do not. It is the pattern of stimuli that we get from kinesthetic and other relevant senses that we recognize as the grasp type of action. When the action habit is done it has to be directed to a specific hand and finger combination which means that an action habit is a device specific action.
30th March 2014 Anticipation
- Backward chaining of anticipation of reward!
- Anticipation requires thinking - predicting what will happen based on experience.
- Thinking uses the currently attended to stimulus as the cue for retrieving / recalling the memory.
Inhibition
The subconscious cerebellum servons are not inhibiting their trigger stimuli from reception by the cortex. They recognize them and use them. It is the cortex that is inhibiting them such that unexpected stimuli attract attention. So all S-habits that are being done are expecting stimuli and it is these that are being inhibited. But the one being consciously expected must be formed. If this is a high-level combination pattern of stimuli and some of its lower level parts are inhibited how does the high level one get formed? It depends on the inhibition mechanism. Conscious (being attended to) expected stimuli and subconscious expected stimuli are all being expected. If inhibition stops lower level source binons from being used in the formation of higher level ones then the consciously expected stimulus may not be formed. And the absence of an expected stimulus can attract attention. The inhibition mechanism should mark all expected stimulus as expected. As all stimuli are processed, the ones marked expected are neutralized. The result may be some that remain expected and didn't happen (missing) and some that weren't expected but happened (extras). The extras should attract attention with a higher priority than the missing.
Attention algorithm [also modified on 31st March]
Attention being attracted to a stimulus is like a reflexive action. Paying attention is equivalent to performing an action. It's a type of action.
1. Binons start in expected or unexpected state. Combine all stimuli - parallel and sequential. Change the expected binons that are found to unexpected. Change the unexpected binons that are found to "extras".
2. Determine what might attract attention. All binons will be unexpected, expected or extras. Expected and extras will attract attention. Some of the extras may be novel. The order of priority should be; Novel, Interesting, Extras, Ones remaining expected (missing)
3. A. Reset extras and expected binons to unexpected
B. Set all next expected stimuli based on past experienced sequences = S-Habits
4. Perform subconscious action habits = servons. Any servon that does not get its expected stimulus should fail. Ones that continue should change their next trigger stimuli binons to the expected state. [No! see comment below]
I'm not sure about this. Is an enabled action-habit that is not being done going to fail? If I'm walking the "avoid obstacle" action habit is enabled or is it? Does it need a trigger stimulus to start it working and only then can it fail or continue? So I don't think walking primes or enables the avoidance task. The sight of the obstacle triggers it and then it is enabled / active. Then if the obstacle is recognized as a wanted item the pick-up action habit is triggered. So what is this primed / enabled state of an action habit all about? Is it that all the possible next expected trigger stimuli that an action habit could get are primed = expected to happen next? The key is the difference between the cortex and cerebellum. The subconscious action-habits (being done by the cerebellum) either continue or fail based on them getting their next expected stimulus. But the cortex is recognizing all the patterns (sequential and parallel) from the execution of habits. And it is only here that expected, extras or unexpected can be detected. But the avoidance task can be triggered and started subconsciously as long as the walking task has been started and is working and avoidance is well practiced. So the enabled state applies to subtasks of the main task when the subtask can also be done subconsciously when the main task is being done subconsciously. It applies to things that can be done in parallel provided their trigger is perceived.
So add to 4. - Any enabled action-habit that gets its expected trigger should start executing and should change its next trigger stimuli binons to the expected state just like a continuing one.
No, continuing subconscious action habits should not interfere with binon expectedness. This is the sole job of the sequential pattern matching / recognition process. It is executing S-Habits. And all experienced sequences will be learnt and only these will deal with expectedness. However the enabled subtasks should still be started if they get their trigger stimulus.
5. If practicing, are there any stimuli that distract your attention from what you are doing? If so the action habit will stop and will not have its redo interest reduced.
6. If practicing an action habit (it must have been interesting or familiar with an interesting goal) then check out its expected stimulus.
A. If it gets its expected final goal stimulus we have a successful action habit. Its redo interest becomes or stays familiar (learnt) and the goal becomes or stays familiar.
Combine it in series with any previous successful one. Combine it in parallel with any active servons.
B. If it gets its expected next (but not final goal) stimulus then the habit continues.
C. If it does not get its expected next stimulus then determine what attracts attention? Use this attention-attracting stimulus to form a new action habit based on the trigger and the act of the one that was being practiced. This is actually done in step 7. What should be done here is just set the state to not practicing.
7. If not practicing (the one being done consciously finished (6A), did not continue but we formed a new action-habit (6C) or there was nothing being done) then;
A. Pay attention to the stimulus from 2
B. Create a new action habit based on the previous conscious stimulus, what was done if anything and the attended to stimulus.
C. Select an action habit to perform. Using the attended to stimulus as a cue determine if there are any interesting action habits to do - worth practicing. The chosen action habit will determine what stimulus from the next cycle to pay attention to.
D. If none worth practicing then find one through thinking. Find one that will produce a rewarding final goal stimulus. This will be a practiced / learnt action-habit so its servon will be started. This is where the thinking loop should be continued until it is interrupted by an unexpected stimulus. Should the thinking loop also start additional servons or should they only be started by a conscious stimulus. Where does boredom fit in - results from repetition of a conscious stimulus?
8. Perform the continuing or new habit.
31st March 2014 S-habits versus A-habits
I've had this idea before but it needs more thinking about. The S-habits (sequences of stimuli) are always being formed and recognized independent of whatever Action-habits are being done. These S-habit binons are the ones that have the expected, unexpected and extra states for attracting attention. The A-habits are things we do. They include the "action" of paying attention. They are the ones that need practice and when learnt can be started and run subconsciously. When we think, do we navigate through the S-habits or the A-habits? Currently I have Adaptron navigating the A-habits because I have been modelling them with goals and redo interest levels. The S-Habits have an interest level too but their second sequential part is not always a goal of an action.
Creating Servons
The avoidance task gets tied into the walking task as a subtask that is enabled and can be started subconsciously while walking when it has been learnt and it is started while the walk is being done subconsciously.
Creating S-Habits
I have previously had STMs on each sense creating sequential patterns of stimuli and detecting repetition. These sequences were being created subconsciously. It seems reasonable that the cortex is creating all these sequential patterns subconsciously and a lot of them end up novel, not combined with others and pruned while sleeping. However those that have attention paid to them become familiar and can be combined with other familiar ones to become more permanent. Now I have to ask myself about which sequences do I want to create. If I have two senses each with one sensor, do I first create the STM sequence per sense and then combine the sequences afterwards or do I combine the two senses and then combine these in sequence. Maybe I should create both. But then the same question has to be asked about which one is the first to get attention paid to it. I believe the rule should be: do not combine any two sequences. Form sequences from one sense or the other. Form sequences of the parallel simultaneous combinations of the two senses but don't combine sequences in parallel.
1st April 2014 S-Habits recognize sequences
Another reason to use S-habits to recognize expected and unexpected stimuli is that a sequence of stimuli can result from actions as well as external events not caused by a person. May as well use the same mechanism to recognize sequences of stimuli.
Quantity
On the news last night there was a report about a shooting in which 4 shots were fired in quick succession. The reporter had obviously asked people about how many shots they had heard. She must have got answers from 3 up to 5 because she reported "between 3 and 5 shots". If I have a sound S-Habit binon that represents the sound of one shot should the quantity be the value in the binon or should quantity be another property binon that is associated with the shot sound binon. I'm leaning towards the later idea because then quantity becomes a sense independent property. See 17th Sept 2013.
When recognizing a 1 dimensional array of stimuli if there is a pattern that repeats beside a different pattern that repeats the relative quantity of the first to the quantity of the second pattern becomes a pattern, a pattern of quantities. I put the IDL for this quantity ratio in the binon that represents the combination of the two patterns. This is a rather nice compact way of representing the quantity pattern but is it general purpose. The 17th Sept 2013 note refers to the 28th July 2013 note in which I am convinced quantity must be a separate property binon. This seems inefficient because there will be so many combinations of quantity = 1 binons with other property binons. No - only quantity ratio / pattern binons will exist. But aren't quantities of 1 and 2 symbolic? Currently I use the value in a binon to help identify it. This is needed for level 1 binons because the value is the IDL / ratio representation.
And the question is: does the subconscious recognition of sequences count the repetitions? I have previously said no. The subconscious sequence recognition has to highlight unexpected stimuli that occur and missing ones that were expected. So it must have an idea what to expect given the first stimulus. I have previously used the idea that it expects it to repeat. Then any change is unexpected. This is the idea of habituation. If this is used at all levels of sequences then it has no need to count occurrences of a familiar stimulus or sequential pattern of stimuli. This would seem to suggest that sequential quantity is only available if attention is paid to the stimuli.
Expected, Unexpected
There are stimuli that were expected that were not perceived which I have called missing. This does not occur. One just gets unexpected stimuli instead of the expected ones. Unexpected ones will always show up as a novel stimulus at the lowest level or cause a novel sequence at a higher level. All the expected ones will be the second part of a sequence in which the first part has just been perceived. So when an unexpected stimulus occurs we pay attention to the novel level 1 stimulus or the novel sequence perceived.
When there are (1) two novel stimuli from different senses, (2) a novel combination from another two senses and (3) a novel sequence from a fifth sense, which attracts attention first? It would seem reasonable that one should learn to recognize the (1) stimuli first, the (2) stimulus 2nd and the (3) sequence last. This is because the combination and sequence are comprised of familiar / learnt stimuli. So this should be the order in which these take priority for attracting attention.
2nd April 2014 Goal achieved
What I have been doing once a novel action habit is practiced and it gets its goal is to stop and wait to see what attracts attention. I think I should be paying attention to the goal instead.
3rd April 2014 Action learning
As a result of my test run yesterday, in which the performance of attention paying action habits are distracted by a novel sequence, I am starting to think of solutions or reasons for the problem. One possible idea is that learning action habits does not need to go through the 3 phases of Novel, Interesting and Familiar. Novel action habits are practiced and they become interesting and interesting ones are done at a lower level of concentration to confirm them and then they are familiar. Familiar ones somehow become servons so they can be done subconsciously. The confirming performance is probably the one that converts the action habit into a servon. Maybe it is only at the thinking level of concentration, which I think is the same as the start servons level of concentration that novel stimuli can distract an action habit from being performed. Or maybe only attention action habits (no act being done) require one performance to be learnt. Or maybe when a novel sequence occurs attention is distracted to the 2nd part of the sequence that was unexpected rather than the novel sequence. The novel sequence is that which indicates the unexpected stimulus but it is not the unexpected one. It’s the stimulus that caused the novel sequence that was unexpected.
Unexpected stimuli
The novel sequence is not the unexpected stimulus. It just highlights the fact that the 2nd part was not expected. So unexpected familiar stimuli will cause novel sequences. At level 1 a novel or interesting stimulus will be the unexpected one. At higher levels an interesting stimulus will be the unexpected one. This will be the second time that the two familiar parts that makes up the sequence have occurred. The first time the sequence occurred the sequence was novel. But the sequence can't become interesting unless attention is paid to it. Or is this rule too restrictive. Maybe stimuli subconsciously go through the cycle Novel, Interesting and Familiar just based on their subconscious perception. We have stimuli habituating subconsciously. So why not have sequence also habituating subconsciously? This would mean all stimuli and sequences become familiar subconsciously, without attention being paid to them.
Attracting attention
The result is that level-1 stimuli that are novel or interesting are unexpected. And any stimulus that is the second part of a sequence that is novel or interesting must be familiar and unexpected. The order for attracting attention is then Novel, Interesting, Unexpected and Familiar.
4th April 2014 Subconscious flush
If your mind is subconsciously building sequences of stimuli and recognizing these patterns and then you pay attention to one of these senses how much of the sequence are you conscious of? Can you recall a complete sentence that was said behind you even though you were listening to someone else who was in front of you speaking to you? Usually you can only recall a very short portion of it. But your subconscious is creating sequences that are recognizable so that it can habituate on the familiar ones and alert you if there is an unexpected one. At some point it has to let go of sequences that are too long. How long is too long? What criterion is used to determine too long? And then when you pay attention to that sense and get a small piece of that sequence any previous part of it must be flushed.
9th April 2014 Independent sensors
When recognizing patterns from a one-dimensional array of sensors adjacent sensors are dependent on each other because they are beside each other. The pair wise combinations of widths that are formed are based on adjacent widths. The width patterns become position independent. An alternate approach is to treat all sensors as totally independent of each other and form patterns from all possible pairs of sensors. Then combine these pairs based on the common pair and binon lattice network structure. Those sensors that continue to have a co-incidental dependency will show up at higher levels in the network. An 8 x 8 two-dimensional array has 64 sensors. The possible un-ordered pairs are N(N-1)/2 = 64*63/2 = 32*63 ~ 2000. The possible ordered pairs are twice this at about 4000. But since we want independent sensors we use the un-ordered pairs. For each pair a binon is formed for the pattern representing the contrast between the two sensors. Each sensor is given a sensor number, so they are always combined in the same way to form the pairs.
10th April 2014 Combinations
The challenge with the independent sensor approach is the exponential explosion of combinations at higher levels. Even if you only combine sensors in pairs when their intensity reading is significantly different you end up with very large numbers of possible combinations at higher levels. This approach may work if you had the required number of binons processing in parallel but with a sequential processor the time delays become impractical. Exploiting the dependency between sensors to process adjacent widths is far more efficient.
11th April 2014 A-Habits versus S-Habits
From my first run of MorseDecoder today I have come up with the question; Can action habits that involve no action (do-nothing) be represented as S-Habits? Which then begs the question can actons be pointed to by S-Habits and thus do away with A-Habits? After some thinking on my whiteboard I have decided that neither will work. S-habits are necessary to recognize unexpected events and must recognize them whether or not any action is being performed. Action habits are required to connect trigger with goal and actions performed between them even though there may be many events between the action and the goal. The trigger for an action habit is also the perceived stimulus plus the expectation of the goal, not just the trigger stimulus. S-habits do not allow for any intermediate events because they are for recognizing sequences. So an action habit that does a series of do-nothings is one in which you would be conscious of waiting for a particular sequence of stimuli to occur before you then did something that involved an action. I suspect action habits are what our frontal cortex is forming. It is associating stimulus patterns with motor programs. And the motor programs are the acton hierarchies.
13th April 2014 Perceived instead
If an action habit (A) is expecting a certain goal stimulus (G) but it gets a different stimulus (D) instead, a "new" action habit (B) is formed out of the previous trigger (T), the act (a) performed and the different stimulus (D). However, this "new" action habit (B) may not be new. It may have been experienced before and be familiar. A = T a G and B = T a D. If this is the case then when A was the current habit being practiced expecting the goal G the action habit B must also have been enabled because it could and in fact did happen. Since B is familiar it should become the previous habit for combining with the next action habit that will be triggered by D when it happens.
Now what if it is a sub-acton of the current action habit that does not get its expected goal stimulus? It gets a different stimulus instead. If the sub-acton were novel or interesting I would expect the current habit to stop. But if it were familiar does it get combined in parallel?
14th April 2014 Potentiated / Primed / Enabled
The idea of an action habit being primed is not new. It corresponds to Gallistel's idea of potentiated, the idea of mental set in problem solving, which is also called Einstellung in cognitive science. From my perspective an action habit represented by an acton must first be enabled (set) and then if or when its trigger stimulus is perceived the acton fires. When it fires it enables its sub-actons at the next level down. Lowest level actons that fire, send their enabling signal to the device they drive.
Acton structure
An improved data structure for actons might be, for each stimulus have a list of actons that can be / have been done and for each acton have a list of goal stimuli that can be expected. Thus given a trigger stimulus and acton performed there are multiple possible goal stimuli. Each acton has only one trigger. Each acton may enable multiple sub-actons. An acton may enable a device instead.
17th April 2014 A-Habit continuing
To determine whether the current action habit being practiced should continue I was using an algorithm that checked to see if the intermediate goal stimuli were being perceived. However a better approach is to check if any of the possible enabled actons will get their firing stimulus. If any actons will be fired by the current set of perceived stimuli then the action habit being practiced will continue. Otherwise an unexpected sequence has occurred.
18th April 2014 Activation
1st source activates binon – expecting 2nd.
2nd source fires binon, which activates all target binons or performs an act.
If there is no 2nd source in the next cycle, the binon is not active anymore.
25th April 2014 Unexpected Stimulus
I have been designating the lowest level-1 stimulus that caused a novel sequence as the unexpected stimulus. So if the novel sequence occurs at level-5 in the binon lattice network, the two level-4 sequence binons must have been familiar. One might think that the second level-4 sequence binon was the unexpected one since the sequential combination is novel. However the first half of the second level-4 sequence binon was not unexpected, only the most recent level-1 part was unexpected. This means that when we are distracted by an unexpected loud noise no part of the sound that preceded it can be retrieved from the sense. This also means that when we switch our attention to a sense we can only retrieve a very short piece of the stimulus equivalent to a level-1 binon. In humans this would be the shortest possible sound to which one can react. For example one cannot react fast enough in the middle of piano note that lasts for maybe a quarter of a second. However one can react while a tuning fork is still ringing. So level-1 sound binons for humans might include up to a quarter of a second of a sound sequence.
This also leads to the observation that trigger and goal stimuli for action habits to start, finish and continue are these level-1 stimuli. The binary lattice network of actons is there to group the acton sequences as tasks that are combinable, doable and reusable.
Acton execution
The task of going to the bathroom to brush ones teeth (1) consists of the sequence of tasks, get out of chair (2), walk to bathroom (3), and brush teeth (4). The task of walk to bathroom (3) consists of the parallel tasks, walk down corridor (5), open doors (6) and avoid obstacles on the floor (7). When task 2 is being done, task 3 and 4 are enabled but their internal sequences or parallel parts are not enabled. When its trigger starts task 3, all of its subtasks (5, 6, and 7) are enabled. But they are not started unless their trigger occurs. And their internal subtasks are not enabled. But the task of walking to the bathroom (3) and its parallel subtasks must be disabled by the start of the sequential task brush teeth (4). This means that sequences of sub-actons must be distinguishable from simultaneous / parallel sub-actons. When a sequence gets its second acton fired the first acton must be collapsed. However, it may remain enabled so it can loop?
27th April 2014 Levels of complexity
I have previously thought about ways of recognizing patterns independent of their level of complexity. This is essentially where a pattern is composed of parts which are also complex parts. A solution may be to add a property to a binon to indicate that its two parts have overlapping subparts or the two parts are not overlapping but adjacent instead. Then high level parts can be combined as though they were level-1 parts. But there must be criteria that determine this. This is also the property I need for actons when the two sub-actons are done in sequence and the start of the second sub-acton disables the parts of the first sub-acton. The two sub-actons do not have any overlapping sub-tasks.
Applying this idea to pattern recognition would seem to suggest that after the largest overlapping familiar patterns have been formed they are then combined with their adjacent ones no matter what are the levels of complexity. Or maybe the strategy is at every level (e.g. level 7) first combine any adjacent familiar level 7 parts (14 sub parts), then combine any of the level 7 parts which have a familiar and overlapping level 6 part (8 sub parts). Then do it again for the level 8 parts created. Adjacent familiar parts that are the same are combined with a count / quantity. Finally the largest (highest level) familiar adjacent parts are combined independent of their levels of complexity.
April 2014 LinkedIn Discussion
Getting back to the original question = What kind of answers would you expect from a theory in order to explain consciousness "end-to-end". One of the answers that I would expect is a functional one. Being a software analyst / software engineer by trade I would expect a data structure and an algorithm that uses that data structure, such that when the algorithm is executed it exhibits the same behaviour that we as humans attribute to each other when we judge each other to be conscious.
Obviously there is no test for consciousness - we can only make a judgement based on externally visible/measureable behaviour and our own experience with it. Another one of the answers should be how the continuous / analog world is converted into symbolic representation for recognition and vice versa for controlling devices to perform action.
Yes, I would expect the "theory" to contain a process description (algorithm and data structure) of what "goes-on" to produce the phenomena of consciousness. Ideally this process description (functional description) should be detailed enough to be programmed in an information processing machine. So I expect an information processing kind of answer.
Note that this is only one kind of answer that should make up the "theory". Another kind of answer should also deal with the physical components (biological or electrical or mechanical) and their interactions that comprise the "machinery" which performs the functionality.
Information is represented in the states of matter. And information is transmitted in the form of energy. Or you could look at it the other way around. The states of matter represent information. And energy transmits information.
4th May 2014 Adjacent or next
Combining two P-Habit binons, possibly of different levels of complexity, because they are adjacent to (beside) each other in sequence is equivalent to the next to each other in the time dimension of S-Habits. However if these two complex parts start occurring next to each other frequently enough the lattice binon structure of the next to each other sub-parts begins to form. This can happen such as eventually the two complex parts combine completely at all levels to form just the one high-level lattice binon network that represents the combination. Until this happens the two different level parts are treated as a binon in which the parts are next to each other with no overlapping subparts.
I'm going to call these binons that have two non-overlapping parts that might be at different complexity levels Next Binons and they represent N-Habits. To form them, do their two binon part (which only contain overlapping binons) need to both be familiar? Do next binons go through the Novel, Interesting and Familiar states? I think since they must be learnt and the fact that we want to learn the higher coincident occurrences the answer is yes. Then the question is once we have two familiar N-habits that occur next to each other, do we form a binary lattice of them? And the answer would seem to be yes. We learn the pattern of next binons.
Algorithm wise this might work as follows. Level 1 binons are all adjacent by default. Combine the adjacent ones and create level 2 binons that will all have non-overlapping level 1 sub-parts. Some of these will be novel or interesting and not combinable to form level 3 binons. But the familiar adjacent ones will be combinable. Combine them to form level 3 overlapping part binons. Any unused level 2 binons because it has non-combinable level 2 binons before and after it, is put in the level 3 binon list at the right place to be in order assuming a linear array of sensors that is being processed. Then the level 3 list of binons are combined based on adjacency and familiarity just as though they were all level 2 binons.
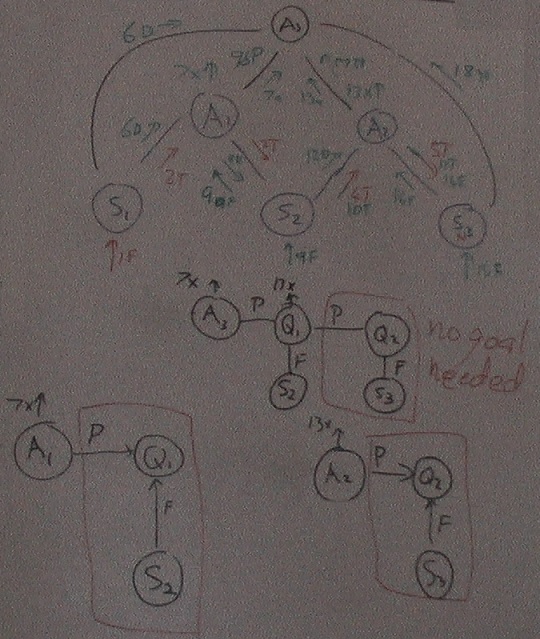
16th May 2014 Acton goals
I am forming sequential combinations of two familiar actons into higher level actons. These higher level ones are initially novel and then interesting when formed. But they have no goal because the lowest level most recent acton is unexpected and it is the only one left to combine with what comes next. However, when the higher level acton becomes learnt (familiar) it stays on the done / completed list and gets assigned a goal stimulus.
22nd May 2014 Repetition
The on and off pattern of the Morse code dit and dah sequence that repeats must habituate at the level 2 of sequential complexity and thus would not form any higher complexity sequences.
Letters need to be pleasant. The goal is to recognize Morse codes so when a letter is received it is pleasant. The action habit should stop when the letter occurs. The action habit should start when the current situation and an expected letter form a pattern that identifies the action habit.
Current situations by themselves would always be priming possible action habits but one also needs the thought / anticipation of a goal (desired letter) to fire / start the action habit. The anticipation of a letter results from thinking using past experiences.
1st June 2014 Habituation
Binons habituate. What they do is saturate and don't stimulate their target binons if they have just fired. This only happens for familiar binons. Binons are first novel when they are created. Then they become interesting when they are stimulated by their two source binons. When stimulated a second time they become familiar and can then saturate. The end result is that familiar binons only fired when there is a change. Once they have fired they must then experience a cycle in which they do not fire. Then the next time they are stimulated they will fire.
Actons are stimulus & act combinations. The act part can be a primitive act or a pair of actons. The rule that two source binons must both be familiar before their combination binon is created also applies to the formation of acts. Both the actons in an act must be familiar. The familiar state of a binon is equivalent to the learnt state of an acton. However, actons are on the output (efferent) side of the hierarchy. They are combined when they fire together or in sequence, whereas binons are combined when they are stimulated. Actons fire when they are used in an action habit. To form an act that is a pair of actons the two actons must be familiar / learnt and have fired one after the other. Actons go through similar states to a binon. If an acton has been created and it fires then it is novel. The second time it is used it becomes interesting. The third time it is used it is learnt. It stays in the learnt state from then on. An acton cannot saturate / habituate like a binon because it can be fired / used repetitively.
Action habits consist of a trigger stimulus, an acton and a goal stimulus. The stimulus part of the acton is the same as the trigger stimulus of the action habit. So effectively the action habit is an acton and goal combination. The rule that two source binons must both be familiar before their combination is created also applies to the formation of action habits. The acton must be learnt and the goal must be familiar. Action habits have three states just like actons and binons. They are created when a learnt acton has been performed and a familiar goal binon perceived. They are then in the novel state. When they are novel there is a desire to practice / redo them. When they are practiced and the same goal binon occurs they change to the interesting state. When they are interesting there is desire to confirm / redo them. When they are confirmed and the same goal binon occurs they change to the learnt / familiar state. At this point they are successful action habits and can be started consciously but done subconsciously.
I've said before that the two binons that represent the current situation (trigger stimulus) and the desired goal stimulus identify an action habit. When thinking we match the current situation with the trigger stimulus of a learnt action habit and use the desirability of the goal stimulus to determine whether to start performing it. If the goal stimulus is not desirable we still think about the goal. Thinking then matches the goal stimulus with the trigger stimulus of another learnt action habit and we think about its goal. If the current situation matches with the trigger stimulus of a novel or interesting action habit we will want to practice or confirm it by performing it. However, note that the desirability of a goal stimulus must be a pleasant or unpleasant value. The interest in a goal stimulus cannot be novel or interesting because it must have been familiar to be used in the formation of the action habit. But this makes me question the need for the acton and the goal to be familiar to form the action habit. Surely when we perform an act and we get an unexpected result stimulus we remember it and want to try it again to see if it repeats. The unexpected result stimulus would become the goal and it may have been a novel or interesting stimulus.
I should use a parameter that indicates the speed of learning. If slow then a binon needs to go through the states novel, interesting, and familiar. If medium then a binon needs to go through the states novel and then familiar. If fast a binon becomes familiar upon creation.
8th June 2014 Purpose of S-Habits
S-Habits are the sequential combinations of two P-Habits from the same sense or sense combination / configuration. Thus they are the sequence of two stimuli which may be two S-habits with an overlapping common part. They are useful for detecting repetition when they saturate / habituate. And if this repetition is conscious an action can be generated to disrupt it. They are also useful for highlighting the unexpected stimuli when combining a familiar next P-Habit stimulus. When the combination is novel or interesting then the P-Habit being added must be unexpected. The A-Habits with the "do-nothing" act in them provide for the formation of S-Habits where the trigger and goal stimuli are from different senses, whereas S-Habits are formed with stimuli from the same sense.
I have been thinking that an S-Habit cannot act as a trigger or a goal of an A-Habit. But is this true? What about the "twang" sound acting as a trigger or goal. See 12th Nov 2013.
9th June 2014 Creating S-Habits
I realized last night that I should not be creating S-Habits automatically in the background as the action habits are executing. I should only be using the S-habits that already exist to determine if a P-Habit stimulus is unexpected, expected or a repeat. It is the execution of the action habits that cause the S-habits to be created in the first place.
On further reflection and while modifying code I realize that I do not need S-Habits at all. The currently executing action habit has the list of next expected goal stimuli and the done tree contains the last conscious sequence of P-Habit stimuli. But I will have to implement the parallel executing action habits to recognize repeating patterns.
11th June 2014 Actons
Last night I realized a different structure for actons. I had been thinking about how to use them to represent S-Habits and provide the same functionality as S-Habits. Specifically I was thinking about how to detect repetition using the current actons. If an acton contained a "do nothing" act then the acton was only determined by its stimulus part. An acton has been equivalent to the traditional S-R (stimulus - response) relationship. And an action habit was the combination of an acton and a goal stimulus (P-Habit). This made an action habit into the T-R-G structure in which T-R is the acton and T = Trigger stimulus, R = Response act and G = Goal stimulus. And actons are combined into higher level actons if they are done sequentially and are learnt. Thus an S-Habit could be represented by a sequence of "do nothing" actons. But then I realized it would be more appropriate to make the acton from an R-S structure. When the R part is a "do nothing" act then the tree of actons will represent the S-Habit. The last acton in a series of such actons can be recognized as soon as the last stimulus in the S-habit occurs. There is no need to wait for the R part of the last acton to be done. Then I realized that implicit in any S part there is the instruction to attend to the appropriate sense, level and sensor/property (where) to obtain the pattern recognized (what).
This now simplifies the definition of an action habit as equal to any level 2 or higher acton. For example, using Ps for P-Habit stimuli, lower case As for primitive acts (e.g. a1, a2 ... etc.) and upper case As for actons.
- The sequence of stimuli and acts is: a1 P1 a2 P2 a3 P3 a4 P4
- The level 1 sequence of actons is: A1 A2 A3 A4 where A1 = a1 P1, A2 = a2 P2 etc.
- At level 2 the actons are A5 A6 A7 where A5 = A1 A2, A6= A2 A3, and A7= A3 A4
- At level 3 the actons are A8 A9 where A8 = A5 A6 and A9 = A6 A7
- And at level 4 the acton is A10 = A8 A9.
No, I still need to associate the trigger with the goal and an action in between to represent an action habit. This approach helps to identify S-Habits and ones that repeat. But it does not address the representation needed for automatic (cerebellum) action habit execution which is the S-R pattern, no goal required.
So there is no change in the original definition of an acton. But an action habit should be changed to have two input binons representing the trigger and goal and one output pointing to the acton to be done. Since the action habit has the two stimuli as inputs it will represent the S-habit.
12th June 2014 Goals
I have been trying to determine if an A-habit based on a particular acton should have one or more goals. If one gets numerous resulting stimuli (goal stimuli) after doing the same action in the same situation one starts wondering if what you do has any effect on the outcome. If one gets a reoccurring outcome one can form an action habit with the outcome as the goal. If later the outcome changes then a new goal is established. Does the shift to the new goal stimulus take place immediately as soon as the resulting stimulus happens the first time? It does not if the original goal was learnt and familiar. The new goal must become learnt before it replaces the original. If the original goal was pleasant then it might take even more than two occurrences of the new goal to replace the original. If the original goal was not pleasant (just familiar) but the new goal was pleasant it might replace the original goal on just one trial. If we just stay with novel, interesting and learnt values it would seem that having two goals for the A-habit with a particular acton would be sufficient. The most recent one would be the one used for deciding the redo interest of the A-Habit. Should a new goal occur it would become the most recent and the A-habit would become novel again. No. No. The A-habit should be uniquely identified by its trigger and goal stimulus. The acton required to get from the trigger to the goal might change but not the trigger and goal combination.
June 2014 E-Mails and responses
Dear Mr. @Brett N. Martensen,
Your simplistic and growing model reminds me of http://www.google.com/patents/US7778946, the model that we studied and played with for a while. You may find some of our works at www.neuramatix.com
Hi Isabel, I'm answering your questions in reverse order :)
You can get a basic description of how a decision tree works at Wikipedia: http://en.wikipedia.org/wiki/Decision_tree
It is effectively a series of If [condition] Then and Else decision nodes. It is used starting at the root node and continues to refine the decision based on the series of conditions that are tested. If you have ever played 20 questions in which you get either a yes or no answer and must determine what the thing is, then you are using a decision tree. The typical first question: Is the thing animal or mineral? The tree works from the root to the leaves. Perceptra forms trees but does it in the opposite order, from the leaves to the root.
I have tried providing the stimuli/examples/answers to Perceptra in many different orders and the answer is that it is agnostic (it makes no difference) to order. It learns at the same rate independent of order. As far as it is concerned there is no such thing as simpler versus more difficult examples. They are all patterns to be recognized.
I will try to explain the grounding of the network as follows. The input information originates from a linear array of sensors. That is a set of sensors that are strung out in a list, in order, they are adjacent, beside each other as in a long row. They each have a position in this row. Also they are all of the same sense. This means they are all measuring the same type of energy (sound, light, temperature or pressure, etc.) A simplified example would be the sensors in an ear. They are all measuring sound energy. Each sensor provides a measurement of the energy intensity/level that it detects. In the ear the sound energy intensity measurement would be the volume. In the ear each sensor would be tuned to detect the volume at a certain pitch / frequency.
Thus each sensor position would correspond to a different frequency. Most likely the sensor at the start of the row would be tuned to the lowest frequency and the one at the end of the row tuned to the highest frequency. Ordered kind of like the keys on a piano. However this is not a necessary constraint / condition for the recognition of the patterns.
When two or more adjacent (beside each other) sensors measure the "same" intensity value within the just noticeable difference (you can't tell the difference between their values) this provides for a width of two or more. In the paper in Figure 4 there are 2 9's, then one 3 and 5 6's.
This gives you a width of 2 sensors beside a width of 1 sensor beside a width of 5 sensors.
You now have the width pattern 2,1,5. This is a one dimensional shape. To represent this in shape binons the 2,1 pattern and 1,5 pattern are represented by level 1 shape binons. Then the 2,1,5 pattern is represented by combining these two level 1 shape binons into a level 2 binon as in Figure 6 - the left level 2 shape binon. This process is repeated up the tree to represent more complex patterns. Note that the binons represent a category of patterns. A row of 16 sensors that provide the widths 4, 2, 10 would be recognized by the same level 2 shape binon because the ratios 4/2 and 2/10 are the same as 2/1 and 1/5.
The same process can be applied using the sensor intensity measurements that are beside each other without any consideration of widths. The 9,3,6 values provide for a one dimensional contrast pattern. If you still have trouble with this approach just let me know and I would be happy to answer.
Hi Kim-Fong (note I got you name spelt correctly this time :))
The process works in unsupervised or supervised mode. If you give it labels it will associate them with the binons (supervised) and if it has no labels it will still continue to classify the patterns (unsupervised). Providing labels on an occasional basis results in Semi-supervised learning.
The approach will work using combinations of senses (multi-modal). Each sense results in a network of the property binons from that sense and then these binons are further combined across the senses. However, senses must be treated as independent, rather than dependent like the sensors in a linear array. But a simple technique for combining independent binons allows for the same binary lattice network to be used.
I am currently still researching the process of combining the binons with motor actions (which I call actons). I have several approaches but am still seeking the simplest yet most general approach which deals with trigger stimuli, goal stimuli, primitive acts and also uses the binary lattice network structure. This structure must also be used for anticipation and thinking.
Hi Isabel, Once again I will answer your points in the opposite order.
Structurally a decision tree and binary lattice network differ in that in a decision tree you can get to a node using only one possible path from the root to the node. In database terminology you have a one-to-many recursive relationship. In a binary lattice network you have many paths to any node. This is a many to many recursive relationship. Then the other key difference, as mentioned previously, is the direction in which they are navigated when in use.
New binon creation at level 1 takes place as soon as a new ratio of values (widths or intensities) is found in an input sample / stimulus. If the level 1 binon with the ratio already exists it changes its state. A binon goes through three states - New, Interesting and then Familiar. When a binon is found a second time it becomes interesting. When it is found the third or subsequent times it is familiar and remains in that state.
Level 2 and higher binons are created only when their two source binons have been found and they are both in the familiar state. This avoids the immediate creation of all levels of binons that could be extracted from a single sample - commonly known as the combinatorial explosion problem. In this way binons that represent the more frequently reoccurring and coincidental patterns are created and used for recognition.
In the paper this is explained in the paragraph: "Second, Perceptra uses a simple policy to avoid the combinatorial explosion that would result from the creation of all the binons that represent each stimulus at all the possible levels of complexity. Two source binons must be familiar, that is they must already exist from the processing of a previous stimulus, before they can be combined in the creation of a target binon. This slows down the creation of new binons. Only known patterns are re-used."
A faster learning process is possible using this approach if binons only have two states - New and Familiar. However this creates a lot more binons.
30th June 2014
See the 2014 Scientific Research and Experimental Development (SR&ED) tax credit claim.
Details about the Canadian Revenue Agency’s SR&ED tax incentive program are here.
7th July 2014 Efference Copy
An efference copy is also known as a corollary discharge. It is a copy of the signal output as a response to an action device. This copy is then used as a stimulus for recognizing what was sent to the device. The presence or absence of this stimulus can then be used to distinguish between other stimuli that are caused by the performance of an action or by an external uncontrolled event. The origin of the stimulus could be identified as the device, as though it were a sensor. Note that other sensors attached to the device may also be producing stimuli in parallel with the efference copy stimulus (EC stimulus).
An action habit that is made up of an acton and goal stimulus can now be represented differently. The lowest level Acton is a trigger stimulus and a primitive act. This gets transformed into a sequence of two stimuli, a trigger stimulus and EC stimulus. When a non-EC stimulus is performed attention is paid to its source (sense / sensor combination and level of complexity). When an EC stimulus is performed it is output as a response.
What about action habits representing types / classes of actions?
The EC Stimulus will be part of the goal stimulus that is a P-habit. With many devices activated in parallel the EC stimuli must form a P-Habit configuration.
13th July 2014 Self-consciousness
The brain monitors its processes. These processes produce stimuli that represent such concepts as "I don't know", "I knew that but can't remember" and other places in a process where a failure occurs. It also monitors successes. Effectively these are mental feelings related to the thinking processes. If one were to equate the source of these stimuli to a sense then that sense would be emotional feelings. These are stimuli generated internally in the brain and used to evaluate (determine a value of) its functioning and successfulness towards achieving ones goals. One could call it self-awareness based on a self-representation.
Attention
Attention can be focused (in an effortful way) on learning a task or (in a less effortful way) on a learnt task. While practicing a task it is effortful. While doing a task automatically it is more a case of monitoring the actions in the task. Automatic / learnt tasks are being controlled / done by the cerebellum however every signal / response they send to a muscle goes through the motor cortex at which point the conscious attention to the task can interrupt / override the response if necessary.
July 17 2014 LinkedIn Discussion
Adaptron Inc. is a one man company that I incorporated in 2002 to house my research and provide the software development consulting services (consulting) that I do. I also teach courses for Learning Tree International and do that through the company as well. The company pays me a salary for all of this work. That is about 98% of its expenses. The company makes no profit so each year it claims a Scientific Research and Experimental Development (SR&ED) tax credit from the Canadian government for the research I do.
The SR&ED tax credit works as follows. Take the portion of the salary expense paid for research and add 65% to cover administration of the research. Take 35% of the resulting amount and that can be used as a tax credit towards any profit that is made. If there is no profit the tax credit is paid to the company. So each year, depending on the amount of time I do research, I get between $10K to $40K from the government as funding towards the research I do.
2nd August 2014 Aggregation
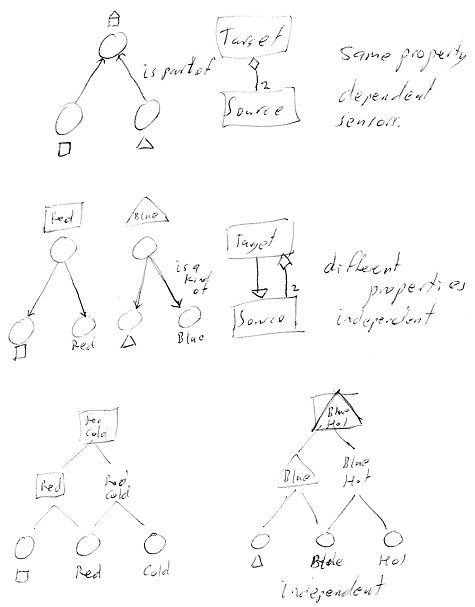
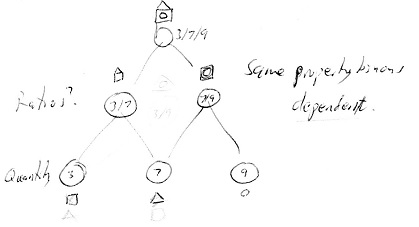
While in Quebec City I diagrammed a Target and 2 Source binons in which the two source binons were of the same property (shape). The UML class diagram says the target binon (a house = box with triangle in top) is made up of the two source binons (a box and triangle). And each box can be part of many shapes. This works because the two source binons are of the same property. You can't say a house is a kind of box and you can't say a box is a kind of house. But you can say they are all kinds of shapes, examples of this property type. The source binons share this common property and thus could be said to be dependent.
However if the two source binons are of different properties (one is shape and the other colour) then the target is made up of the two sources (a red box or a blue triangle). And each source binon can be part of many composite things. But one can also say that each composite thing is a kind of target binon. For example a red box is a kind of box. Since the two source binons are of different properties one could say they are independent.
4th August 2014 Quantities
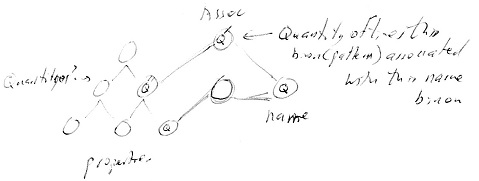
The Association binon could contain the quantity of times that a particular property binon or class binon is associated with a particular name binon. The more frequent the co-occurrence the more likely it will fire? Firing sequence takes the most frequently traversed path through the network. Co-occurrence of familiar binons causes the creation of new binons representing the combination. Subsequent co-occurrence of the familiar binons causes the path to be taken before co-occurrence of novel ones. The count of subsequent co-occurrences makes for even greater precedence.
Generation - top down, attention top down, - Find instead. Given a label find the prototype.
Binons should have a count in them of the number of times they have occurred - numerosity. A target binon could have a number in it that represents the relative number of times its two source binons have occurred - a ratio of the two source binons' quantities. This may be useful in the associative binon to get the most frequently occurring label / name binon. If it's a sequence binon it could be the relative rate of the 2nd source following the 1st source. For P-Habits of property binons the quantity is the number repeats. The dependence / independence of the source binons must determine if the target binon is a ratio or a count? - not sure yet! If a ratio is to be produced then do log(A/B). The result is a symbolic representation.
6th August 2014 Logarithms
The links between binons calculate the logarithms of the source binons' values. This is a neurologically plausible explanation. If the signal from excitatory synapses are added together and the ones from inhibitor synapses are subtracted you end up with the subtraction of one logarithm from another. The quantity in a binon would represent a threshold above which the accumulated signals must be before the binon fires.
24th Aug 2014 LinkedIn discussion
There is no room for free will in a practical / scientific explanation of our brain. Our will cannot be free of the laws of physics, chemistry and biology that govern the functioning and processes of the neurons in our brain.
I would suggest that the purpose of consciousness is to provide a meta level for learning and thinking. Consciousness is the result of a meta level process. It is a process that allows the brain to;
- know what it does not know
- self-correct
- know that it does know but can't retrieve / recall something right now
- learn better thinking styles/strategies
- recall one's thoughts
- think about thinking
- And any other processes required to monitor and adjust another process
The other process being the pattern recognition, motor control and thinking (cognition) that goes on mostly subconsciously between pattern recognition and motor control.
5th Sept 2014 Left and Right binons
The binon has a left and right source. Their order is important because their order may be left minus right and this is different from right minus left. Edges are symbolic but they have a value representing the magnitude of the changes. This helps identify the type of edge. When a binon is recognized multiple times it has a quantity but the quantity is not part of the binon, it is an activation value. The binons identity is dependent on the parts that comprise it.
Left and right source binons are "beside" each other this makes them order / position dependent.
When sensors are independent (not beside each other - no relationship that can be mapped to the concept of beside each other) they still need to be placed in an order so one can create all the n(n-1)/2 pairs of sensors. Then one can combine pairs in which there is a common / overlapping middle binon. This results in the ability to create all possible combinations of the independent sensors. But not all pairs are produced. Binons should be created only when their source binons change at the same time. This requires the time dimension.
If the measured value and quantities are part of the activation values then what is put in the binons value. For the lowest level where dependent sensors are used it is the IDL of the two adjacent sensor values. Then the list of these binons can be counted so that we have a list of binons and the count in the activation tree. The next level would contain binons that use two adjacent source binons and a value (part of its identity) based on the ratio of quantities.
7th Sept 2014 Sum-Product Network
There is an ANN that has alternating layers called a Sum-Product Network (SPN). One layer adds the source nodes together while the next layer calculates the product of the sources nodes. These layers alternate up the hierarchy. It ends up representing the idea of (x+y)*(a+b)*(m+n)* ... etc.
Is it possible that what I need is a ratio count network? One layer does ratios and the next counts quantities. The next layer does ratios of the quantities and the next layer does quantities of these ratios. This is what I have been trying to do in enhancing Perceptra. But it would be nice if the binons represented the ratios and the quantities were in the activation tree. And this is the important distinction. The quantities are transient based on the observation while the ratios are permanent as binons that represent the patterns.
Does this correlate with the spiking signals that are transmitted between neurons? Here the spiking rate is usually presumed to contain the information about what has been perceived. The spiking rates could represent the quantities and a neuron that is tuned to a certain ratios of spiking rates from its source neurons (pre-synaptic ones) is the one that fires. Spikes are transient as are the quantities in the activation tree and the number and configuration of synapses are fixed but changes as learning takes place.
29th Sept 2014 Perceptra 1D
I have been changing the algorithm for the lowest level pattern recognition in Perceptra 1D. This recognizes hand drawn digits using a one dimensional array of sensors that contain the raster scan of the pixel values. At level 0 the binons are formed from the ratio of the reading values in adjacent pixels (from adjacent sensors). Instead of forming both a contrast and a shape pattern independently and then combining them to form class binons, I have taken a different approach. First, contrast level 0 binons are formed for each pair of adjacent sensors. If there are 64 sensors then there are 63 level 0 binons that capture (the edges) the ratio of the two adjacent sensor readings. If the two readings are the same within the Just Noticeable Difference (JND) then the 1/1 ratio edge level 0 binon is recognized. Initially all other JND ratio level 0 edge binons were being produced. But I found for the grayscale images too many of these level 0 edge ratios exist and I was only getting a 33% prediction success rate. So I changed the level 0 edge binons to only be created for a positive, negative or no change edge. Once the 63 level 0 binons have been created then any that are the same binon and adjacent are combined and counted. This removes repeaters. For example, this may reduce the number of level 0 binons to 26. A string of 6 adjacent 1/1 ratio level 0 binons would reduce to a single 1/1 ratio level 0 binon with a quantity 6. Then level 1 binons are formed by combining adjacent level 0 binons. Effectively level 0 binons recognize velocity and level 1 binons recognize accelerations. Each level 1 binon points to the two adjacent source level 0 binons and contains the value which is the Integer Difference of Logs (IDL) of the two source level 0 binon’s quantities. This value is the symbolic representation of the ratio of quantities of the two adjacent source level 0 binons. Then the level 1 binons that are the same but separated by 1 binon (adjacent at the sensor level) are combined and counted. Then level 2 binons are formed from adjacent level 1 binons to form level 2 binons with IDL values representing the ratio of level 1 quantities. Then repeaters at this level (separated by 2 binons) are combined and counted. The result is that level 1 and higher binons represent ratios of quantities of lower level binons.
2nd October 2014 Images versus Bitmaps
I found that if I represent level 0 ratios of intensity at edges based on JNDs I did not get the best recognition rate for images with a range of pixel intensity values. The better prediction was obtained with just creating 3 level 0 ratio binons; one for increase, one for decrease and a third for no difference. If JNDs were used then about a 65% JND worked the best.
3rd October 2014 Perceptra 2 plus Dimensions
I’ve been thinking of how to extend the one dimension approach to 2 or more dimensions. The resulting approach can be used uniformly from the sensors through all the levels of binons that aggregate lower levels. The binons at level 0 are of two independent types; horizontal and vertical. The ratios exist in this array where the horizontal and vertical level 0 edge binons are created. Each entry contains the sensor value as the first integer value. The ratio to the right of this value is the horizontal ratio with the next sensor on the right. The ratio at the bottom of the entry is the vertical ratio with the next sensor below it.
| A | B | C | D | E | F | |
| Row 1 |
1 ¼ ½ |
4 1/1 1/1 |
4 1/1 1/1 |
4 2/1 1/1 |
2 1/3 ½ |
6 3/1 |
| Row 2 |
2 ½ 2/1 |
4 1/1 1/1 |
4 1/1 1/1 |
4 1/1 4/3 |
4 4/3 4/1 |
3 3/7 |
| Row 3 |
1 ¼ 1/2 |
4 1/1 4/5 |
4 4/3 4/3 |
3 3/1 1/1 |
1 1/7 1/3 |
7 7/3 |
| Row 4 |
2 2/5 2/1 |
5 5/3 5/3 |
3 1/1 1/1 |
3 1/1 1/1 |
3 1/1 1/1 |
3 1/1 |
| Row 5 | 1 1/3 | 3 1/1 | 3 1/1 | 3 1/1 | 3 1/1 | 3 |
For any point in the middle of four sensors that form a square there are two horizontal edges and two vertical edges. For example at the middle point between of the top left square of sensors with the value pattern:
1 4
2 4
There are the two horizontal ratios; ¼ above the point and ½ below the point. There are the two vertical ratios; ½ left of the point and 1/1 right of the point. Each ratio is captured as either a horizontal or vertical property level 0 binon.
The pattern of edges ratios is:
¼
½ 1/1
½
Since horizontal and vertical patterns are independent of each other they should be combined as early as possible at the lowest level possible. But if this is done with the horizontal and vertical level 0 binons in each square entry above you lose information on the right and bottom edges. Also the shape represented by this combination is equivalent to 3 squares in the non-symmetric shape of an L rotated 90 degrees clockwise. So the solution is, for each middle point, to first combine the two horizontal level 0 binons (¼ and ½), second combine the two vertical level 0 binons (½ and 1/1) and then combine these two results to represent the 4 entries that represent the 2 by 2 array of sensors. This result is effectively at the location of the middle point of the 4 sensors. Given the 6 by 5 sensor array the result is a matrix of 5 by 4 binons.
Now represent each of these middle point binons with a symbolic letter on a 5 by 4 matrix.
| A | B | C | D | E | |
| Row 1 | G | H | H | I | J |
| Row 2 | K | H | L | M | N |
| Row 3 | O | P | Q | R | S |
| Row 4 | T | U | H | H | H |
Binon G represents the structure:
¼
½ 1/1
½
Binon H represents the structure:
1/1
1/1 1/1
1/1
And binon Q represents the structure:
4/3
4/3 1/1
1/1
The same approach must now be taken with this matrix as the sensor array. However, first any adjacent binons which are the same (i.e. repeat) must be counted because the next higher level binons use the ratio of quantities to represent the patterns.
The resulting ratios are shown in this matrix using the same approach as in the sensor array.
| A | B | C | D | E | |
| Row 1 |
G ½ 1/1 |
H 1/1 1/1 |
H 2/1 1/1 |
I 1/1 1/1 |
J 1/1 |
| Row 2 |
K 1/1 1/1 |
H 1/1 2/1 |
L /1 1/1 |
M 1/1 1/1 |
N 1/1 |
| Row 3 |
O 1/1 1/1 |
P 1/1 1/1 |
Q 1/1 1/1 |
R 1/1 1/1 |
S 1/1 |
| Row 4 |
T 1/1
|
U 1/3
|
H 1/1
|
H 1/1
|
H
|
Note that in Row 2 column B the vertical ratio with the binon at Row 3 column B is 2/1. That is because there are two H binons vertically above this edge. Similarly the horizontal ratio between Row 4, column B and Row 4, column C is 1/3 because there are three H binons to the right in Row 4.
The ratios are now combined as before such that the 4 matrix positions in the 2 by 2 square at the top left:
G H
K H
Are now represented by a binon with the structure:
½
1/1 1/1
1/1
This binon now represents the pattern of values in the nine sensors (3 by 3) in the top left of the sensor array.
12th Oct 2014 LinkedIn Discussion
Mark, You are right about the need for (emotional) feelings in an AGI to reach the "intelligence" level. It is also important to separate out the feelings that result in intrinsic and extrinsic motivation.
Intrinsic motivation is based on the feelings of novelty and familiarity. Novelty and familiarity can be determined by any process that maintains a memory of past experiences and compares current experiences with those memories. It results in the emotions of surprise, curiosity, boredom etc. The resulting behaviour is described as exploratory (this is the phenomenological result of detecting/perceiving novelty and familiarity and pursuing new things (entertainment) and avoiding things you have done before). This is the mechanism that babies / children use to learn most of their knowledge.
Then the extrinsic motivation is based on the feelings of pain and pleasure (I like to use the words pleasant and unpleasant as adjectives rather than the words pain and pleasure because one can have unpleasant stimuli without them necessarily being painful). Here we are dealing with the innate programming that adds feelings / values to our stimuli that are good or bad for the survival and reproduction of the organism. These feelings result in the whole range of emotions that we attribute to things that we decide are good or bad.
But there is another set of feelings that are not often mentioned or categorized this way and those are the ones that our brains produce as a result of it monitoring its own performance, its own processes. These are the metacognition feeling that one might call self-awareness feelings. I attribute these to the phenomena of consciousness. Examples include; knowing that you do not know something, knowing that you do know something but can't retrieve it from memory, having a goal and not achieving it when you perform an action etc. The Sept. issue of Mind magazine had an interesting article about it.
http://www.scientificamerican.com/article/can-animals-or-computers-have-metacognition
Intrinsic motivational feelings and metacognition feelings are necessary for an intelligent process to learn, think and have consciousness. These are the ones I am working on to start with. They are more basic to the functioning of the AGI. The extrinsic motivational feelings provide the organism with purpose. These are the ones which have to be crafted appropriately such that our AGIs / robots behave as we want. These are the ones that can be abused and result in destructive behaviour.
13th Oct 2014 LinkedIn Discussion
Hi Mark A. Negative or positive effect is always involved in any form of feedback from feelings. It's how that effect is used / applied in the process that counts. You can have a process that seeks boredom (familiarity) or explores (seeks novelty). If you want a process that obtains more information about the environment (including its body) in which it operates then the novelty-driven one works better. We judge the exploration approach as positive and the boredom seeker as negative because that's the way our brains work. Negative versus positive is a human value judgement.
A particularly good recent (2009) neuroscience article I read seems to point to the anterior insular cortex as the source of what I have been calling metacognitive feelings. It can be found at: Perspectives - Nature Reviews Neuroscience 10, 59-70 (January 2009)
Opinion: How do you feel — now? The anterior insula and human awareness by A. D. (Bud) Craig [video lecture]
The Abstract = The anterior insular cortex (AIC) is implicated in a wide range of conditions and behaviours, from bowel distension and orgasm, to cigarette craving and maternal love, to decision making and sudden insight. Its function in the re-representation of interoception offers one possible basis for its involvement in all subjective feelings. New findings suggest a fundamental role for the AIC (and the von Economo neurons it contains) in awareness, and thus it needs to be considered as a potential neural correlate of consciousness.
I would be interested in Fred's views about this possibility.
Good feedback / comments. I have certainly been using the term intrinsic motivation in the classic way as described in Wikipedia: http://en.wikipedia.org/wiki/Intrinsic_motivation#Intrinsic_motivation rather than using the distinction between the internal and external source of the feeling.
Bottom line to me from a functional perspective is that all feelings are stimuli. And they all originate from some form of internal source (most likely neurological in origin). The unpleasant / pleasant feelings originate from a source that produces a feeling stimulus value from the interpretation of other stimuli that originate from other sensors. E.g. A touch stimulus originates from a haptic sensor. But some other internal component determines the pleasantness / unpleasantness of that touch. The same would happen for a stimulus originating in our stomach (hunger sensors?) or in our blood stream (thirst sensors?). You might phrase it as: something is adding goodness / badness values to the experienced / perceived stimuli.
For me the other feelings (the ones that are not pleasant or unpleasant) are the ones that are more fundamental to the operation of the processes we call perception, action and thinking. They can and are generated by the processes themselves. Their values can be determined algorithmically and associated with experiences. For example, novelty and familiarity are fundamental to the use of a memory for the retrieval of knowledge and thus recognition. And learning declarative facts and procedural actions can be based on this kind of feedback. Learning also can be based on the pleasant / unpleasant feeling stimuli. But if we can get an AGI working based on the "other feelings" first we have a simpler foundation on which to add the pleasant / unpleasant drivers / feelings.
I can't apologize for my extreme functional approach. I have a very analytical mindset. I'm always trying to understand things. And with my computer science background naturally tend to gravitate toward practical, procedural, informational and logical explanations. Not that I think negatively about a neurological simulation approach to formulating an AGI. This could pay off big time for those such as Fred who have the wealth of knowledge and experience in this subject area. There are lots of good results coming from this field. I read masses of material in this subject area and find it a great source of ideas for my functional approach. A number of my favorite authors specialize in this area. One is Joaquin M. Fuster with his books on the cortex and memory. Other authors in cognitive science / psychology are Marc Jeannerod for Motor Cognition and C.Randy Gallistel for the Organization of Action and the Organization of Learning.
14th Oct 2014 LinkedIn Discussion
Some very relevant research in this area is being done by Kristinn R. Thórisson at the Center for Analysis & Design of Intelligent Agents, Reykjavik University and Icelandic Institute for Intelligent Machines - Menntavegur 1, IS-101 Reykjavik, Iceland. I was at the AGI 2014 conference in Quebec City and Kristinn talked about "Seeds". Software that watches and learns to do things from example. I was most impressed. Lots of details in their paper that can be found at: http://people.idsia.ch/~steunebrink/Publications/TR13_bounded_recursive_self-improvement.pdf. There are also several other relevant papers to which Kristinn has contributed.
2nd Nov 2014 LinkedIn Discussion
Concerning habitual and non-habitual acts - I am of the opinion (not scientifically established yet) that the cerebellum (and not the cortex) is responsible for executing all the habitual acts that we can do, that we have learnt to such an extent that we only have to consciously start them and then they are done by the cerebellum subconsciously to completion or interrupted by a stimulus the cerebellum can't handle. Non-habitual acts are those requiring the cortex (premotor cortex areas as well as primary motor cortex). Non-habitual acts are more complicated and require more repetition / learning before they can be automated and performed subconsciously by the cerebellum. There are lots of papers about the cerebellum's role in performing subconscious acts but I have yet to read any that say that it can perform a long duration act, such as a habitual act that lasts many minutes, such as walking to the Maroubra beach. However, I believe that is what it is capable of doing.
One recent interesting article in Frontiers in Neural Circuits about the cerebellum is: Neuromodulatory adaptive combination of correlation-based learning in cerebellum and reward-based learning in basal ganglia for goal-directed behavior control.
22nd Nov 2014 LinkedIn Discussion
I consider the Turing Test more than adequate for the purpose. The kinds of questions and answers need to be appropriately engineered. And there should be no time limit on how long the test should go for. For example one kind of question might test the machines ability to perform mental imagery and indirectly test its knowledge of vision. The question would be phrased something like this. Imagine drawing a picture from straight line segments, all of the same unit length of one inch and joining them together sequentially clockwise as in the order given with 90 degree angles. Draw the first line horizontally and the second line down from the right end of the first. The third line horizontal to the left and the fourth line vertically up. Now what does the image look like? If it gets that right, then try another question, again starting with the horizontal line and attaching them in clockwise direction. The order would be 2nd line down, then lines, right, down, left, down, left, up, left, up, right, and up. The answer to the first question should be a square and the second should be a cross (like a plus sign).
29th November 2014 Or Operations
Binon And = Binand
Binon Or = Binor
Binor fires if either one of its two inputs occur. It is trained / learns / comes into existence when one of its inputs is active and its output is active. Maybe it starts as a Binand but then only one of its inputs fires simultaneously / coincidentally with an input into one of its target binons – Hebb’s first law about post synaptic and presynaptic fire together.
14th Dec 2014 2-D Combination
My thinking about which edges to combine to represent a 2 dimensional square area of four pixels has changed. If the square 2 by 2 pixel area consists of values A, B, C, and D as follows:
A B
C D
Then the AB edge is combined with the AC to form the first half of the representation of the area. Then the BD edge is combined with the CD edge to form the second half of the representation. Then these two halves are combined. Note that - Edges are the features. An edge is the smallest symbolically representable pattern.
Position and Gaps
Since we can pay attention to the position of an object in the field of view or the pitch of a tune the “where” information of an object must be represented as well as the “what” information. We can direct our attention covertly (without moving our eyes) to an area that is not in the center of our vision. This can only be possible if the position property is something that is represented. For a one dimensional array of sensors such as found in the ear this is equivalent to paying attention to a specific range of pitches. If we then consider the edge as the smallest possible feature / object (the “what”) we also need a position (the “where”) for each edge. But the position is an absolute value. Neurons probably represent this by the position of the neuron on the cortex. But in Perceptra this should be represented as a relative value, possibly the ratio of the gap between two objects and their size. I need to think about the appropriate way to structure this.
18th Dec 2014 Gap representation
Over the years I have had many thoughts and ideas about how to deal with gaps between objects spatially or temporally. Now that my smallest symbolic object is an edge I am devising a new way of representing gaps. What I want to do is represent the edges that make up the gap as “unknown” edges. Two adjacent unknown edges get combined into an unknown edge of quantity two. When two known and familiar edges do not share a common sensor then the two edges are separated by a number of unknown edges and they can be combined with the unknown edges to form a pattern. For example: The pattern ABA results in the two edges at level 1 of AB and BA which can be combined at level 2 as (AB)(BA). The pattern ABBA results in the three level 1 edges of AB, # and BA, where # represents the unknown edge between the B and B sensors. While processing level 3 we check for any level 1 edges that are known and familiar but separated by one or more edges. If they exist we create the two level 2 binons for (AB) # and # (BA). Then combine these to form the level 3 object ((AB)#)(#(BA)). The activation tree for the # binon would contain the quantity of the unknown edges.
This approach seems too complicated. It would be easier to combine all familiar edges no matter what the separation. The gap would be an activation tree quantity. Edges would exist only between sensors where there is a JND between the readings. Then any two pair of edges that share a common middle one would be combined and the value in the resulting binon would represent the ratio (IDL) of the two activation tree quantities.
28th Dec 2014 Gaps
While thinking about 2-D intersections / corners I realized that the direction of change in brightness over an edge is an extra property of the edge. This is either a +ve or –ve IDL value for ratio of the readings on the two sides of an edge. When two adjacent (beside each other) edges in a 1-D array are combined it is better to use the ones which have an opposite direction of change in reading. For example if the pixels have the readings 111144442222 the 1/4 edge is +ve and the next 4/2 edge is –ve. If the values were 111144447777 the edges are both positive ¼ and 4/7. This sort of pattern occurs when the edge from the 1 to 7 values is blurred, spread over a number of pixels and is less useful for recognizing the object. So when it comes to combining edges that are separated by other edges in between (gaps) it is better to combine edges that are opposite in sign.
2-D corners
The same principle as above applies to combining edges between pixels in a 2-D array of sensors when producing corners / intersections. There are two types of edges, horizontal and vertical. Each of these has a positive or negative change in reading. Then there are four corner types, top-left, top-right, bottom-left and bottom-right that can be composed of these edges. Graphically they look like ┌, ┐, └ and ┘. However each of these corners has two types based on whether they are positive or negative in change of reading from the inside to the outside of the corner. Only the correct types of horizontal and vertical edges can be combined to create the valid corners.
Adjacent and gap
I had a good result using adjacent edges and one edge gaps with opposite sign edges in 1-D today. I am getting up in the 75% accuracy range on the first 4000 bitmap hand drawn digits.