2007-11-24
Adaptron Test Run – 1 - Date: 24th Nov 2007
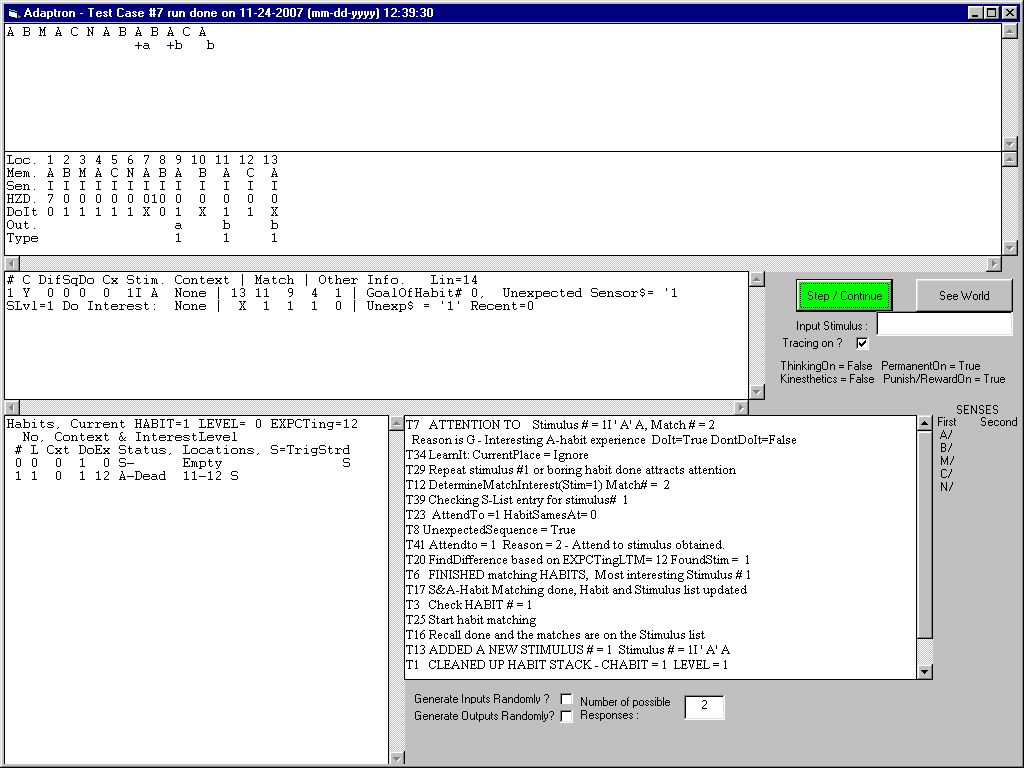
I am trying out a new strategy for response performance. It first goes through all of the responses for a given situation and then it repeats them based on redo interest. At this point it has output a b in response to A expecting a C which it did not get. It got a boring A instead. But it is now going to repeat another b because it still expects a C at experience #11 in LTM. Maybe unsuccessful A habit experiences should loose their interest when they fail. Or when looking backwards in LTM through similar experienced situations the most recent experience with the same response should determine the interest.