
2005
4th January 2005 Thinking
See Adaptron Test Run – 1 – Thinking.
I’ve decided we only do thinking on A-Habits not on S-Habits. Also see note from 27th February, 2004.
6th January 2005
On 9th January 2004 I pointed out for S-Habits the sequence ABC could be recognized as (AB)C or A(BC). I want it to be recognized only one way, ideally (AB)C. See 21st September 2003 note. Then when D follows I would want to build on past experience and recognize ((AB)C)D)
What happens if all stimuli are As? We don’t get A, AA, (AA)A , ((AA)A)A.
We get A, (AA), A(AA), (AA)(AA), (AA)A(AA), A(AA)A(AA), A(AA)((AA)AA))
If we get A and B, it should be?

Thinking
When thinking about the goal stimulus of a possible action we only think about subsequent expected goal stimuli that would result from a subsequent action. We don’t think about the sequential S-Habit that could be made up of the expected goal stimulus and possible next stimuli, thus thinking is all action oriented / goal oriented, not recognition oriented.
But we can think of a sequence of stimuli such as the notes in a musical tune. But here we tend to play it back to ourselves; we don’t have an expectation / idea of the notes.
Thinking about actions and goals works perfectly for problem solving. What about thinking in order to say something? We have this concept / idea we want to communicate and we can think (play it) about what to say, how to phrase it. This is verbal thinking rather than imagery.
11th January 2005 R-Habits / Generalization / Specialization Related to notes of 8th January 2004 and 7th September 2004
First novel stimuli attract attention i.e. kinesthetic a then external A. Then these two are familiar but aA relationship / simultaneous / recognition habit is novel. Then the R-Habit matches as familiar since it is the most general familiar stimulus. If we look at a three sense / feature situation where #’s are senses, the possible pairs (R-Habits – R – Binons) are:
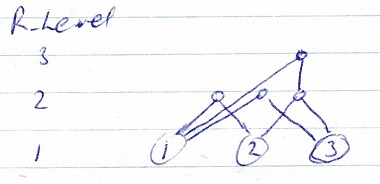
Starting at the lowest R-level and working up from left to right the first novel stimulus attracts attention. If all stimuli at level 1 are familiar, go to level 2 and find out if any of these are novel and on to level 3.
E. G.: values A on sense 1, B on sense 2, C on sense 3
A, B, C become familiar, then AB, then AC, then BC, then ABC.
Now D on sense 3, E on sense 2 and F on sense 1.
They and their possible combinations become familiar. Now get an ABD each of which is familiar itself as is AB. Next (order) things to attract attention are novel combinations at R-level 2 AD and BD, and at R-level 3 ABD.
Now all possible combinations of A or F in sense 1, D or E in sense 2 and C or D in sense 3 have occurred and have been recognized as familiar at R-level 3, 2 and 1. Now sequential habits start to concentrate at the changes between 2 R-Habits occurring because when the executing S-Habit does not get its expected result we pay attention to the R-Habit piece that is different from the expected. This is a more specialized (lower R-level) piece than the whole one received.
E.G.: S-Habit expecting FED and gets AED instead – attention to the A – R-level 1
expect FED get ABD – attention to AB – R-level 2
expect FED get ABC – attention to ABC – R-level 3
In summary, first attend to novel R-Habits lower R-levels first, then to novel S-Habits lower S-levels first. S-levels are determined by length of
S-Habit.
Number of R-Habits based on number of features
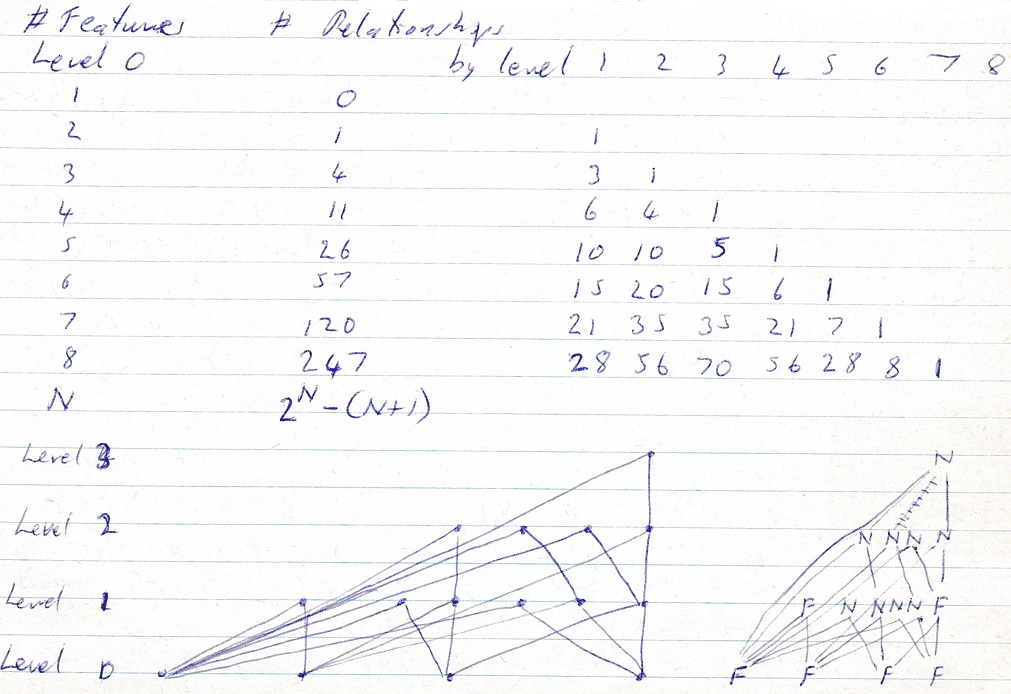
For the sense of hearing the number of features is 1/ pitch and 2/ volume. Sense of time is a different sense. But also have two ears.
For sense of touch the number of features is 1/ place, 2/ pressure and 3/ temperature but each place is like a different sense. Similarly with vision each place can detect 1/ colour and 2/ brightness.
Taste and smell could each be just a single feature although taste may be location oriented.
12th January 2005
Using similar rating of one stimulus is novel and the other familiar the R-Habit tree looks like

I don’t see how this kind of a similarity rating would help.
Similar would be defined when comparing two stimuli. One would have a certain number of features in common with another. This similarity would compare one R-Habit in the tree with the same R-Habit position of another stimulus combination. This would have to involve sequence, the first just received compared with what was in memory. Even when seeing two things as visually similar we have to look at each individually.
As you approach your front door you are surprised because there is a red stop sign nailed to the center of it. The whole image is novel even though the sign is recognizable as familiar as is the door and the context. But then your attention is drawn to the stop sign as being the unexpected part of the scene, implying that you are executing a habit which has the pre-stop sign scene as the expected scene.
Q: Can an R-Habit have an expectation? Or do we start up an S-Habit using the context as a trigger or does the currently executing S-Habit at the time of the surprise / novel situation carry on executing? In other words the surprise was not enough to stop you in your tracks!
Things to do list of 6th September (see 9th April also)
Done #3
Done #2a for two features
I think I solved #5 – also may solve #6
Add: 9/ Add a sense of time.
13th January 2005
On 1st September 2004 I described an algorithm of determining the emotional feeling of a stimulus based on its resulting / next stimuli feeling. This was a linear algorithm. The trigger stimulus feeling increased linearly and decreased linearly (more rapidly if punished). I think an algorithm which increases rapidly and then decays slowly might be more realistic. E.g. Add trigger and result feelings and divide by 2.
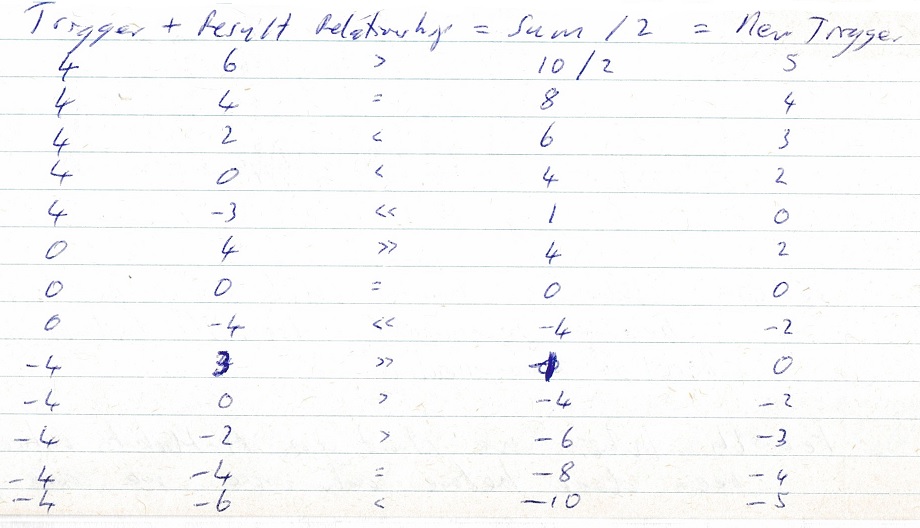
However this may have a problem when a loop occurs and both trigger and result have feelings of 1.
Recency versus reward
If a stimulus has been rewarded in the past but not recently it still holds some promise of being rewarded, thus gambling. So as long as the stimulus’s feelings are positive the habit (even with no expected novelty and has been learnt) should be done. Each unsuccessful (not rewarded) performance will reduce the positive feeling for the stimulus.
Each S-Habit being done has a concentration level equal to the interest level of its expected result / goal. I should make the numbering scheme consistent with that used for novelty and punishment / reward. Also permanent stimuli should use the same number scheme with zero being neutral.
Something like:
Interest / Desirability Meaning
Level
0 Neutral
1 Learnt – no interesting result
2 Unlearnt – novel binon – needs repeating
3 Wanted result
4 Good result (reward)
-2 Boring – loop
-3 Feared result
-4 Bad result (punishment)
Note: levels 0 and 1 could merge
3rd February 2005
4th February 2005
Q: When a stimulus that has a non-zero feeling becomes permanent does its feeling get reset to zero - neutral?
5th February 2005
When we start an A-Habit which has been done before only once, we are practicing it. We execute it at the level of concentration 2. So we don’t get distracted and can prove that it really does get the expected result. When the result / goal is reached we mark the habit learnt.
Q: An R-Habit (recognition) does not need such repetition. It forms on first occurrence and is recognized on second and subsequent occurrences. Maybe S-Habits should also be learnt on first occurrence, i.e. the sequence does not need to repeat before we label it as learnt!?
This would mean given the sequence
1 2 3
A B A
On receiving the second A the expectation is for a B, but B is familiar (has no good feeling). The expectation is for nothing new so it reflexively produces a response. It does not start an S-Habit to recognize a 1. As a result, the hierarchy of S-Habits will only form based on permanent underlying stimuli. Stimuli will have to become permanent (no more actions to try) before a sequence of stimuli will be recognized (collapsed).
When ABA is received and A and B have both become permanent I have decided that S-Habits should be started to recognize both A (BA) and (AB) A. This will generate two entries on the S-List. One with context A stimulus (AB) and another with stimulus X in LTM. Both should be available to attention but only one will attract it.
7th February 2005
On 9th January 2004 I was investigating sequential recognition and possible combinations that need to be recognized. If we consider two unique stimuli we get at level 1 (single occurrence) only two possibilities: A,B. At level 2 we get AA, BB, AB and BA. At level 3 we get A (AB), B (AB), A (BA) and B (BA), (AB) A, (AB) B, (BA) B and eight others, half of which are redundant.
Given 2 stimuli, Level 1 2 possibilities 0 redundant
Level 2 4 possibilities 0 redundant
Level 3 16 possibilities 8 redundant
Or 2 stimuli length N 2N unique possibilities
3 stimuli length N 3N unique possibilities
4 stimuli length N 4N unique possibilities
…X stimuli length N when recognized using pairs and pairs of pairs etc. is the problem.
8th February 2005
When dealing with 2 features, if the relationship of the 2 is familiar and it is started as an S-Habit then the 2 source features should not be used to start any background S-Habits because they are “contained” in the trigger relationship. If either one of the 2 source features is novel obviously it will attract attention. If both source features are familiar but the relationship novel, then the new relationship will attract attention.
Now if we have 3 source features any combination of the features that is novel will attract attention starting with each feature individually, paired features, and finally the 3 of them. Based on generalization before specialization (discrimination) the familiar threesome will be attended to if all else are familiar. If it is permanent then it is used to start up an S-Habit to recognize possible next stimuli. But its twosome and source features should not be used to start any background S-Habits because they are “contained” in the trigger relationship. If there is no expected next relationship (no S-Habits being done) then what attracts attention in the next relationship should be the largest (longest) familiar feature (all 3 different from trigger) or twosome that changes relative to the trigger.
E.g. Attention is attracted to change and to the largest change – the whole threesome, or the twosome, or the individual features.

If there is an expectation (active S-Habit) then it is the difference between it and actual stimulus that attracts attention using same idea as above - The largest familiar difference / change.
A key idea from this is that when no S-Habit is active the expected stimulus is no change in any of the senses / features or = previous stimulus.
1st May 2005
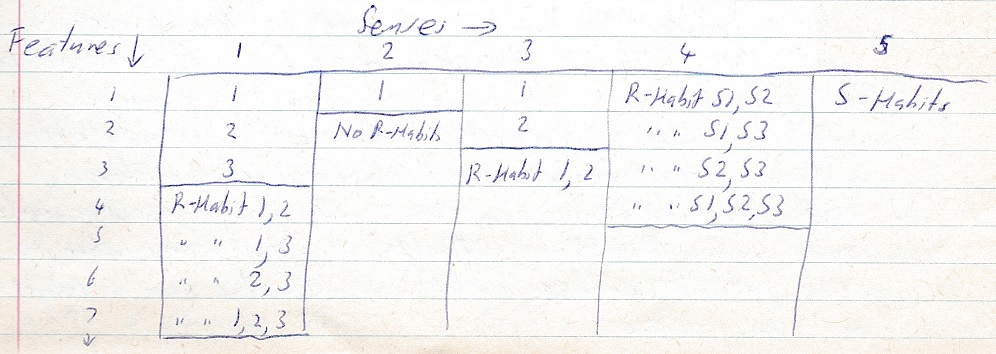
Change senses around so that sense 1 -> N are for N senses, each of which has M features.
Relationship – habits per sense follow features per sense. Then come between / across sense R-Habits in the N + first sense and then S-Habits as the last sense.
8th May 2005
We start A-Habits as a result of the trigger stimulus causing us to think about the expected result which we want. We start the A-Habit at a concentration level such that we can continue to think about the expected results of currently experienced stimuli which may result in starting a second or third, etc., A-Habit in parallel with the first. E.g. we decide to go downstairs for a bite to eat because we are hungry. We proceed to go downstairs. We see a hammer on the table and decide to put it away. Pick it up and take it to the workroom. The first A-Habit (go downstairs for a bite to eat) is interrupted by the second A-Habit (take hammer to workroom). The first one was not being concentrated on at a high enough level to stop the second one from being started. And the second one uses the same resources (legs) as the first one. But if the second one does not use the same resources, two A-Habits get done in parallel. E.g. first A-Habit is pick up fork with left hand, second A-Habit is pick up knife with right hand. Both use same resources (eyes) but we do learn to pick up both knife and fork simultaneously with practice, sharing the sense of vision. If absolutely no resource conflicts we can learn to do two things simultaneously, e.g. talk and walk or peddle and steer. This learning is only possible if we start an A-Habit and give it a low concentration level. This would be done for an A-Habit that has been learnt.
11th May 2005
The dimensions to hearing are: (see 11th January 2005).Two ears, from each ear, at an instant in time, a range of frequencies in Hz with a certain number of Hz resolution – differs at different frequencies and volume for that frequency. So if range is 100 Hz –> 5100 Hz = 5000 Hz range with the 10 Hz resolution equally across range then 500 stimuli each with a volume in decibels range from 0 dcbl –> 120 dcbl in 1 dcbl resolution –> 120 possible volumes. But no stimulus from a frequency with no volume.
So hearing has 2 senses
500 features
120 values
Taste has 1 sense
5 features (salt, sugar, bitter, sour, glutamate? +?)
50 values - intensity?
Smell has 1 sense
1000 features? – chemicals
50 values – intensity?
Touch has 1 sense
1000’s locations – points on body surface
2 features – heat, pressure
50 values each? intensity? gm/cm2?
Sight has 2 senses
1000’s locations
3 features – 3 colours
50 values? – brightness
23rd May 2005 R-Habits
On 12 January 2005 the R-Habits at levels 3++ combine stimuli from different levels. This is not necessary since can combine stimuli from just previous level as documented on 9th January 2004 and still get same effect.
Instead of Use
29th May 2005
Using “your front door” as an example of R-Habits that are novel or familiar. If each season you have a different wreath on it, i.e. a Christmas one in November-December-January and a spring one in February-March-April, then when it changes you are presented with a change that is different from your expectation. The new stimulus (image) is totally familiar. The door and wreath are the same as last year at the same time but the part that has changed is the wreath so your attention is attracted to the wreath.
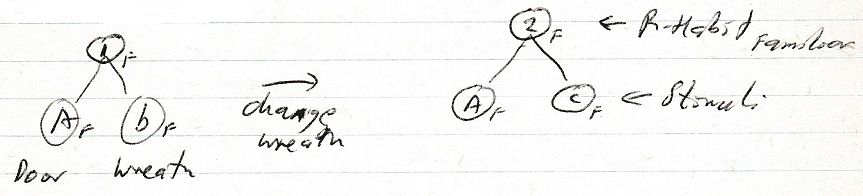
Attention attracted to the change b -> c both familiar.
If, however, one day instead of a wreath a stop sign is put on the door, now a stop sign is familiar but the combination is not – it is novel.
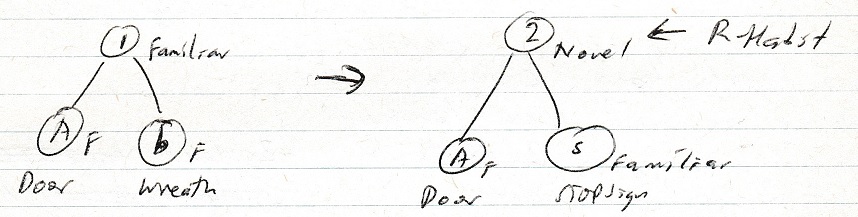
No (The combination (novel) attracts attention) No - The stop sign attracts attention. It’s different from expectation. If however one day instead of a wreath a novel painting appears on the door, does the combination (generalization first) attract attention or just the painting. Just the painting. Lowest level novel stimuli attract attention because an expectation was active. If no expectation and you see a door (yellow) of a new house which has a stop sign on it, the door / sign combination attracts attention. Each (yellow door and stop sign) is equally out of place, which implies there are still expectations at work as to what you expect at the front of a house (a door). It is only when there are no expectations that the generalization is done first.
Based on 8th February ideas when there is no active S-Habit, i.e. no expected next stimulus then the expectation is for the same stimulus and it’s the difference from this same stimulus that will attract attention.
16th June 2005
I’ve implemented a mechanism for determining which stimuli have changed from the last set of stimuli as needed based on 8th February table. Now I need to recognize the group (largest) of changed stimuli. These form an object because all the characteristics of an object change with the object – or object characteristics stick together. So given 3 stimuli where S = same as before and D = different, M = mix:
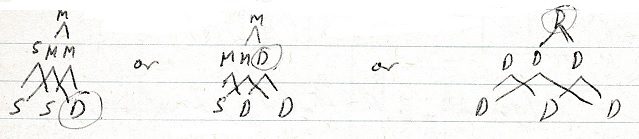
We want the highest level D to attract attention.
With 4 stimuli:
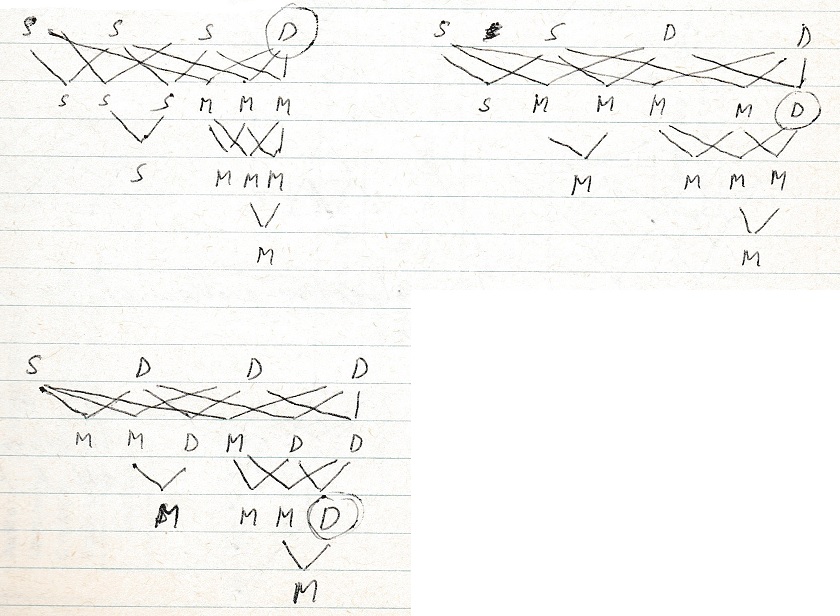
The same is true for novelty. We want the highest level novelty to attract attention.
Just interpret these diagrams with S = familiar, D = novel and M = similar.
17th June 2005
Note about novelty being the same interpretation as differences in yesterday’s note is not correct. Novelty can arise from a new combination of familiar stimuli. If any primitive stimuli are novel then the R-Habit combination of these novel stimuli is the one we want to pay attention to. Obviously the novel ones will be a subset of the different ones for primitive stimuli. If the S’s are all familiar and the D’s are novel then the M’s are also all novel. But because they don’t attract attention, nor stored in LTM they remain novel combinations not yet attended to. If there are some familiar D’s then some M’s may be familiar and others novel.
20th June 2005 Alternate R-Habit structures:
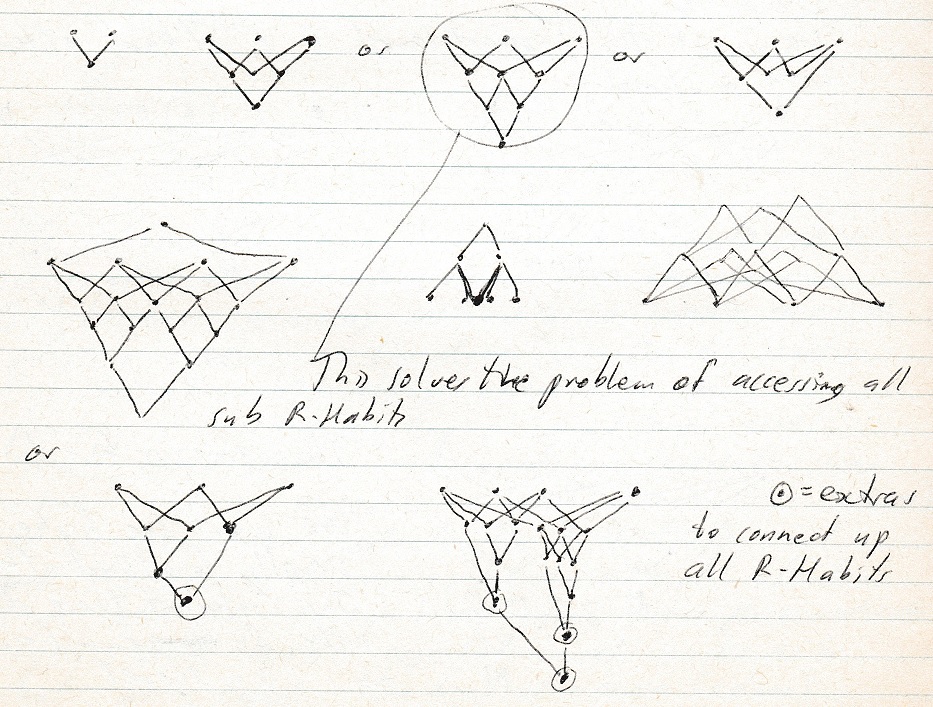
When there are no expectations - whatever changes attracts attention.
30th June 2005
See the 2005 Scientific Research and Experimental Development (SR&ED) tax credit claim.
Details about the Canadian Revenue Agency’s SR&ED tax incentive program are here.
11th July 2005 P-Habits – Parallel Habits
P-Habits were previously called R-Habits for Relationship or Recognition Habits. They are instantaneous recognition habits that take 2 simultaneously occurring input stimuli and produce the resulting stimulus.
When reading a recent Scientific American’s article on the functioning of the eye, I noticed that the final cells send an on or off signal. So I thought
P-Habits maybe simplified if rather than each location on a 2 dimensional sight grid or location on a linear array (ear – frequency) having an amplitude / intensity which has a value 0 -> 255 it should have a binary value 0 or 1, on or off.
Next it is important for P-habits to recognize patterns in the array or grid independent of location. So a single on cell in an array of cells should be recognized at any place in the array. So using R-Habits

12th July 2005
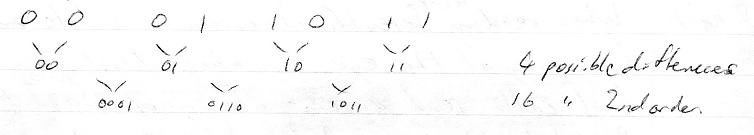
2nd order differences recognize any 4 bit pattern. Given 4 source stimuli which have only 2 values (ON/OFF) then can only have 24=16 possible
R-Habits to recognize all combinations. Lets deal with 3 stimuli.
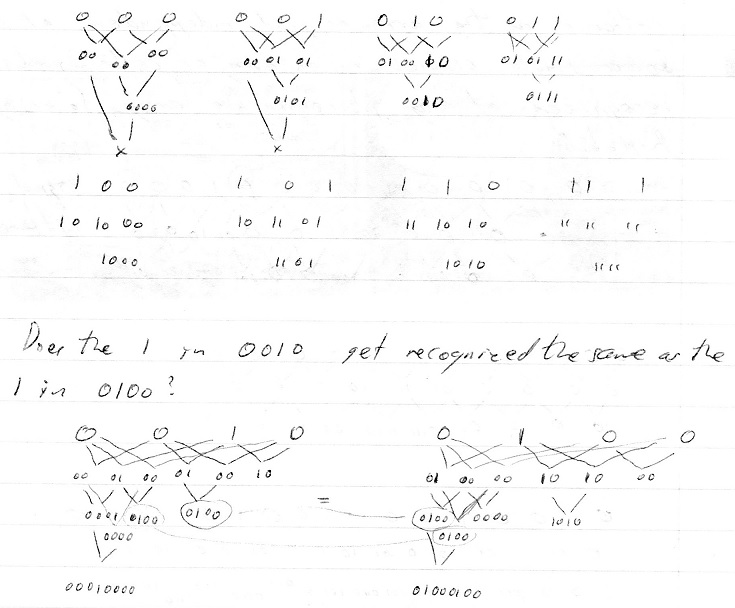
But recognition works when there is a change in the stimulus from the previous one. So if a sound occurs we recognize just the changed frequencies. Any sounds that stay at the same volume are not incorporated into the new stimulus. So our attention is attracted to / we recognize the “same differences”.
It can’t be location independent recognition because it has to be well grounded – The area of attention has to move to the change.
15th July 2005 Permanent Stimuli
I should try a strategy with permanent stimuli such that even if it is permanent when it repeats i.e. AA then boredom should set in and a reflexive response should be tried. Thus it would remain continuously active in an all A’s environment – possibly trying responses randomly.
7th August 2005 Location independent recognition
I realized this morning that sight, hearing and touch pattern recognition needs to be location / address independent. A “+” sign in the middle of field of vision is just as well recognized in peripheral vision and in many different sizes. Thus it is a difference between adjacent neurons that is recognized i.e. “same difference”. So the value of the difference, independent of the pair of source binons, needs to be kept and compared with any other pair of source binons.
14th August 2005 Changes
The attention is attracted to a change in input and pattern recognition is done on those inputs that have changed. This implies that sensors have a memory of their last “reading” / “measurement” and compare it with the current one. If there is a change – within the resolution of the sensor it “speaks up” so attention can be attracted.
7th November 2005 Categories of sensors
Categorizing sensors from the simplest to more complicated.
1A, B Simplest – Single detector which is binary – it is on when it detects something and goes off when it is not. The change from on to off and off to on attracts attention. Its values of reading are zero and one (range) or just 2 states.
2A Next Simplest – Single detector which takes on a set of values. A change in its value attracts attention. The set of values corresponds to readings / symbols where there is no sequence involved so that just change occurs same as on and off. Like the previous one with multiple – more than 2 states – current Adaptron sensors.
2B Next – A single detector which measures a range of possible values. A change in its value attracts attention but since the range has a sequential nature the amount of change becomes a value as well. This is a simplest sensor where there are more than 2 states and instead of going up one or down one a change is detected as going up or down a given amount. The resolution recognition capability of this amount is worse with larger changes. For +1 or -1 it is always a perfect match. Thus a change from 250 to 251 = +1 is recognized as the same amount of change between 10 to 11 = +1. Similarly, +2 or -2 are always recognized. But +10 is easily mistaken for +11 or +9 because recognizing the amount of change accurately is not so important when this amount of change occurs. A possible resolution of amount of change scheme might be based on each power of 2 and halfway above and below it. So buckets might contain:
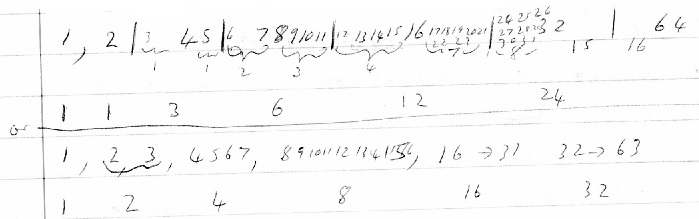
A scheme like this would be similar to how well we recognize the distance between 2 points on the skin or the time between 2 beats. The problem with recognizing the amount of change accurately to high resolution stems from the need to save the amount of the 1st change and comparing it with the amount of a 2nd change. You can’t put the 2 amounts beside each other and compare them. This also occurs with comparing 2 changes in brightness or 2 changes in pitch. The (wider the difference) greater the amount of change / difference the less resolution / accuracy we have.
Simplest – Single detector – binary – 2 states or 2 values with sequence – means 2 types of the simplest detector. With just 2 states (1A) a change occurs and has no value of amount of change. With 2 sequential values (1B) – zero and one we have an amount of change, -1 and +1.
2B – Buckets for next simplest detector with sequential values
Range 1 2 3,4 5,6,7,8 9,10,11,12,13,14,15,16 17-32 33-64 65-128
Size 1 1 2 4 8 16 32 64
To detect the difference between a change of +9 and +10 we have removed the temporal nature of the comparison and converted it into a spatial one – simultaneous representation of the two amounts of change. Also the amount of change has to be sequential in time – you can’t have “reset” between the two stimuli otherwise you introduce a 3rd stimulus – depending on the capacity duration of the senses to retain a 1st stimulus. If you are doing increase in brightness comparisons and you introduce a black period of very small duration between the two brightness stimuli the eye looses the value of the 1st brightness. Or 2 notes on the piano. If it’s quiet for too long between the notes one has to commit to memory the 1st note to do the comparison with the second rather than allowing the sensor to do the comparison.
Thus type 2B sensors provide an absolute reading and an amount of change reading whenever a stimulus changes based on their time duration / resolution / polling rate. Using the last bucket scheme above if the absolute values range between 0 and 2n then have 2(n+1) buckets to recognize
i.e. values 1 -> 8 (1 -> 23) differences are 8 buckets = -8,-7,-6,-5 -4,-3 -2 -1 1 2 3, 4 5,6,7,8
A difference of zero is no change in the absolute value of the stimulus and this never attracts attention. But when attention is paid to a stimulus – sensor – only the absolute value is returned.
9th November 2005 Changes attract attention
A changing stimulus attracts attention but it is actually unexpected changing stimuli that attract attention. Habits that are active “absorb”, “reduce novelty of”, “use up” changing stimuli because they are expected by the habits. The remaining ones – unexpected attract attention.
10th November 2005 Sensors
1A and 2A sensors are “discrete” while 1B and 2B sensors are “continuous”. Or the adjectives can be used to describe the stimuli these sensors detect. The discrete objects in the real world from which only continuous stimuli come are recognized via the discrete nature of the amount of change they cause. i.e. the parts of an object all cause the same amount of change – the parts stick together and change in unison.
For a 2B sensor eventually every absolute value has been experienced and only those values that are meaningful – play a part in - have been learnt. Learning then starts to use the amount of change data independent of the absolute values to recognize patterns for S, P and A habits.
4th December 2005 Generalization – Specialization
Two simultaneous events on different senses, but at least on two different features, A on one and B on second are followed by action that is rewarded. When A occurs again with anything neutral instead of B, generalization kicks in and the A-B is recalled and the action repeated in order to get reward. Same if B occurs again with a neutral value instead of A. This is generalization, only need 1 of the original stimuli to trigger action – a version of similarity. If A-B and action was punished then A or B will cause the action not to be repeated and since it is never done again it will never be found out if A was the cue or B was the cue.
If C-D & action1 was punished and A-B & action2 was rewarded what happens if we get A-D? First A-D is novel and maybe good and bad cancels each other?
If you have a graduated stimulus on a single sense / feature such as pitch then how do we generalize / specialize? First base our actions on similarity such as low pitch, medium pitch, high pitch. Then by learning we start to discriminate within the low pitches until we can no longer discriminate based on the resolution of the sensor.
Design – divide the 256 [continuous in the real world (quantized by sensor)] graduated stimuli into 8 groups of 32. Then each 32 is divided into 4 groups of 8. Then each 8 is divided into 2 groups of 4, which are divided into 2 groups of 2, which are divided into 2 groups of 1. 5 levels of 8 bits = 3 + 2 + 1 + 1 + 1
Change amounts also similar structure, +1, +2, +3+4, +5+6+7+8, +9 to 16, +17 to 32, +33 to 64, +65 to 128, +129 to 256,
0, -1, -2, -3-4, -5 to -8, -9 to -16, -17 to -32, -33 to -64, -65 to -128, -129 to -255 = 19 levels